Cloudera Data Platform (CDP) is a hybrid knowledge platform for large knowledge transformation, machine studying and knowledge analytics. On this sequence we describe tips on how to construct and use an end-to-end big data architecture with Cloudera CDP Public Cloud on Amazon Web Services (AWS).
Our structure is designed to retrieve knowledge from an API, retailer it in an information lake, transfer it to an information warehouse and ultimately serve it in an information visualization utility to analytics finish customers.
This sequence contains the next six articles:
Architectural issues
The aim of our structure is to assist an information pipeline that enables the evaluation of variations within the inventory worth of a number of corporations. We’re going to retrieve knowledge, ingest it into an information warehouse and ultimately plot it on charts to visually achieve insights.
This structure requires the next capabilities:
-
We’d like an utility that extracts the inventory knowledge from an internet API and shops it in a cloud supplier’s storage answer.
-
We additionally want the flexibility to run jobs that rework the info and cargo it into an information warehouse.
-
The info warehouse answer should be capable to retailer the incoming knowledge and assist querying with SQL syntax. Additionally, we wish to make certain we are able to use the fashionable Apache Iceberg desk format.
-
Lastly, we use the analytics service natively current within the Cloudera platform.
With this in thoughts, let’s take a better take a look at what CDP affords.
CDP Structure
Each CDP Account is related to a management aircraft, a shared infrastructure that facilitates the deployment and operation of CDP Public Cloud providers. Cloudera affords management planes in three areas: us-west-1 hosted within the USA, eu-1 situated in Germany, and ap-1 based mostly in Australia. On the time of writing, us-west-1 is the one area through which all knowledge providers can be found. The official CDP Public Cloud documentation lists obtainable providers per area.
CDP doesn’t host knowledge or carry out computations. Within the case of a public cloud deployment, CDP makes use of the infrastructure of an exterior cloud supplier – AWS, Azure, or Google Cloud – to carry out computations and retailer knowledge for its managed providers. CDP additionally permits customers to create personal cloud deployments on on-premises {hardware} or utilizing cloud infrastructure. Within the latter case, Cloudera gives the Cloudera Supervisor utility that’s hosted in your infrastructure to configure and monitor the core personal cloud clusters. On this and subsequent articles, we’ll focus completely on a public cloud deployment with AWS.
CDP Public Cloud permits customers to create a number of environments hosted on completely different cloud suppliers. An surroundings teams digital machines and digital networks on which managed CDP providers are deployed. It additionally holds consumer configurations akin to consumer identities and permissions. Environments are impartial of one another: a CDP consumer can run a number of environments on the identical cloud supplier or a number of environments on completely different cloud suppliers.
Nonetheless it needs to be mentioned that some CDP providers usually are not obtainable on all cloud suppliers. For instance, on the time of writing solely environments hosted on AWS enable the CDP Information Engineering service to make use of Apache Iceberg tables.
The schema beneath describes the connection between CDP and the exterior cloud supplier:
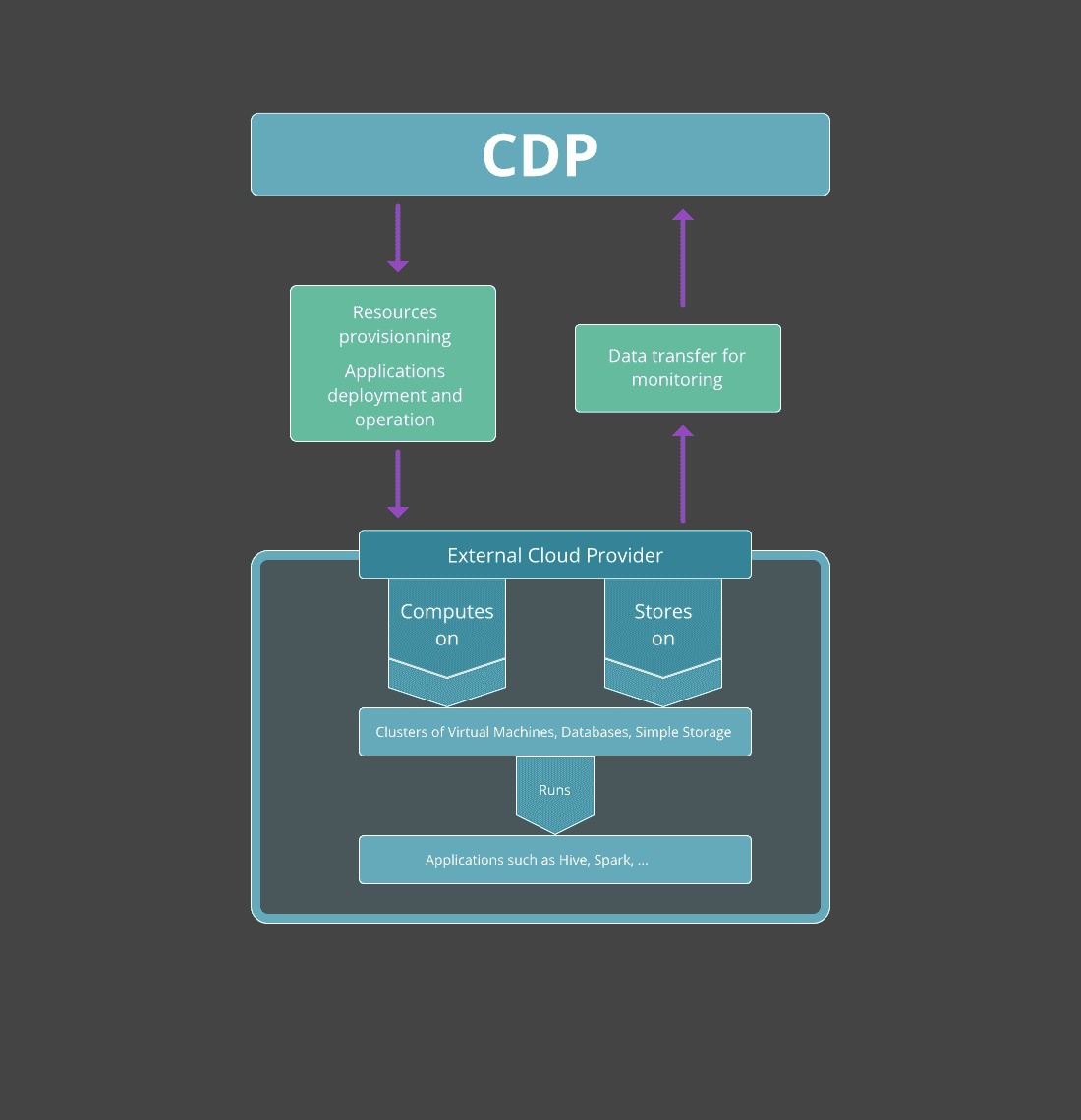
CDP Providers
The beneath picture reveals the touchdown web page of the CDP Console, the net interface of the platform, within the us-west-1 area:
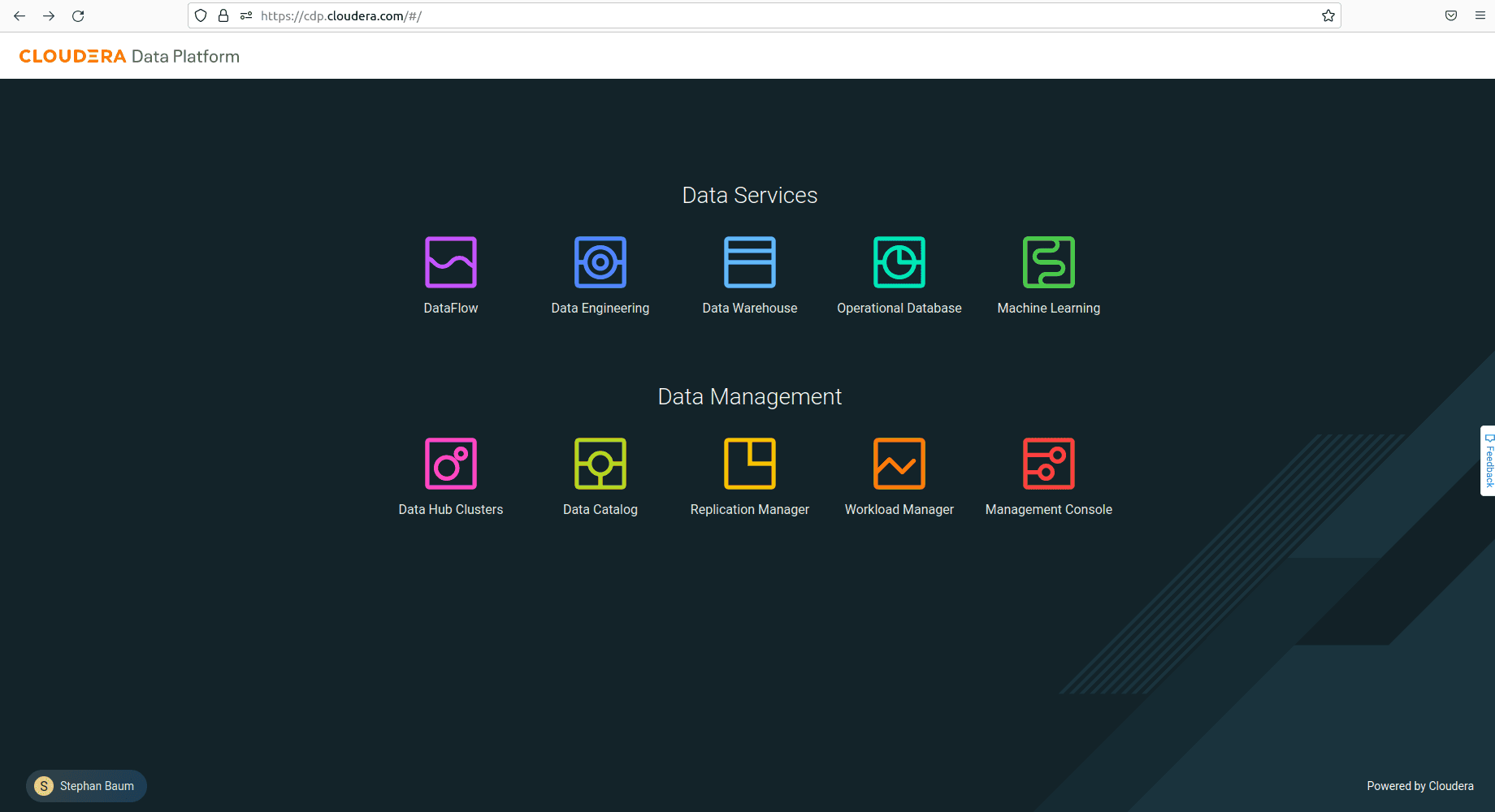
The left-to-right order of the providers displayed within the console is logical because it follows the pipeline course of. The DataFlow service extracts knowledge from numerous sources, whereas the Information Engineering service handles knowledge transformations. The Information Warehouse or Operational Database providers shops ready-to-use knowledge, and at last, the Machine Studying service permits knowledge scientists to carry out synthetic intelligence (AI) duties on the info.
Let’s describe the providers in additional element, with a give attention to those we use in our end-to-end structure.
DataFlow
This service is a streaming utility that enables customers to drag knowledge from numerous sources and place it in numerous locations for staging, like an AWS S3 bucket, whereas utilizing triggers. The underlying element of this service is Apache NiFi. All knowledge streams created by customers are saved in a catalog. Customers might select from the obtainable flows and deploy them to an surroundings. Some ready-made flows for particular functions are saved within the ReadyFlow gallery which is proven beneath.
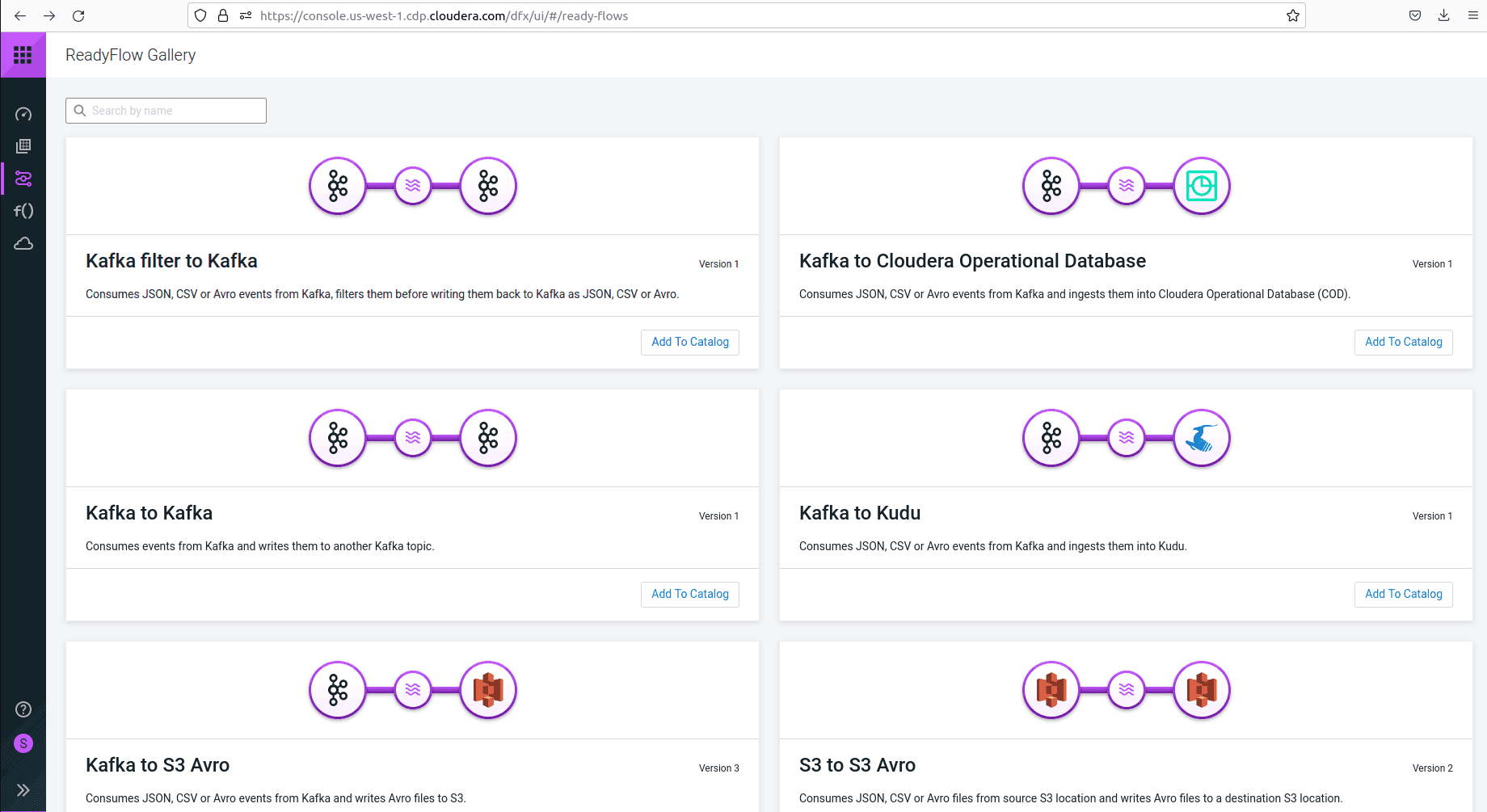
DataFlow is both activated as a “deployment”, which creates a devoted cluster in your cloud supplier, or in a “features” mode that makes use of serverless applied sciences (AWS Lambda, Azure Features or Google Cloud Features).
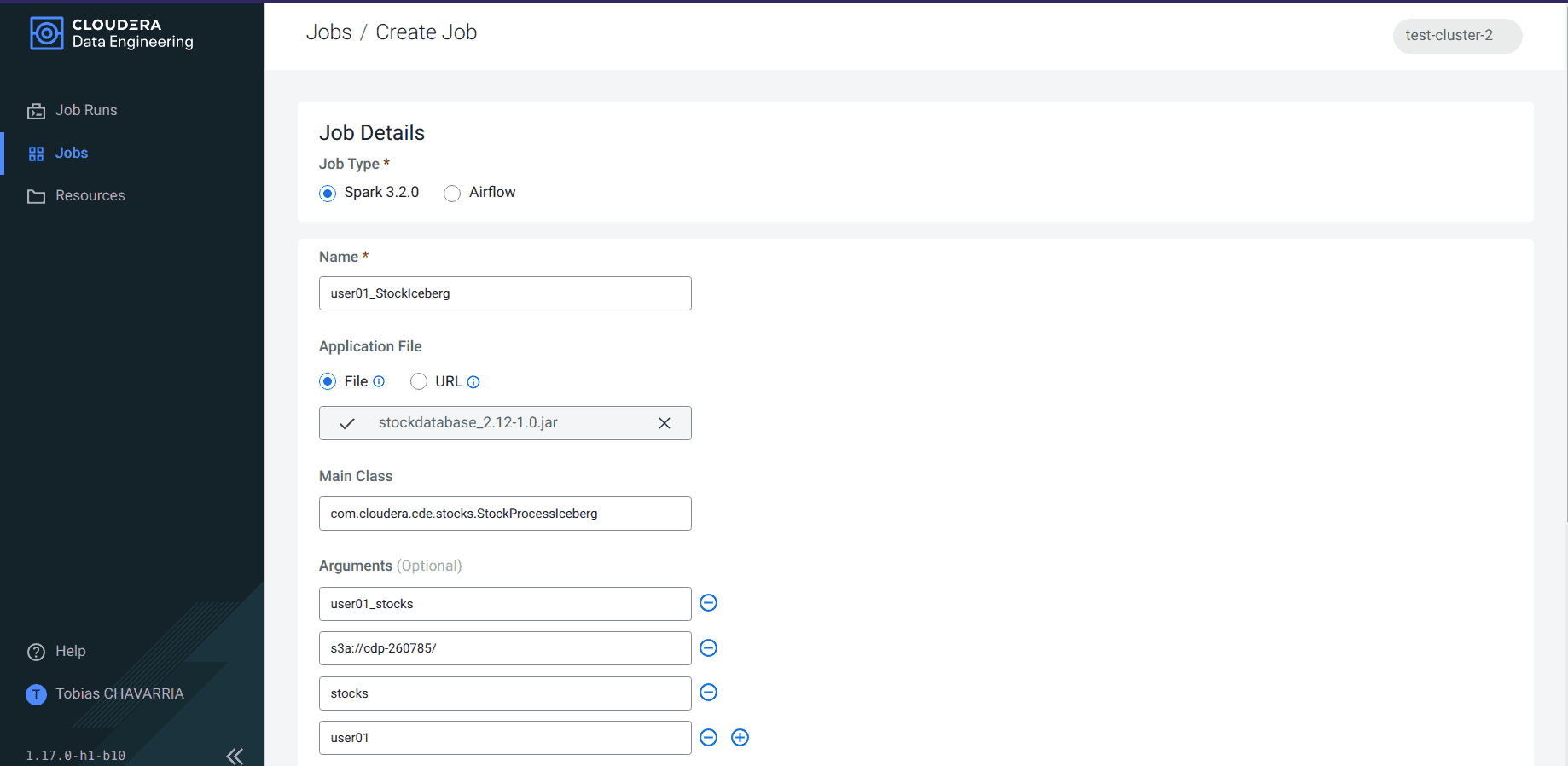
Information Engineering
This service is the core extract, rework and cargo (ETL) element of CDP Public Cloud. It performs the automated orchestration of a pipeline by ingesting and processing knowledge to make it usable for any subsequent use. It takes knowledge from a staging space by the DataFlow service and runs Spark or AirFlow jobs. In an effort to use this service, customers have to allow it and create a digital cluster the place these orchestration jobs can run. The service additionally requires digital machines and database clusters in your exterior cloud supplier.
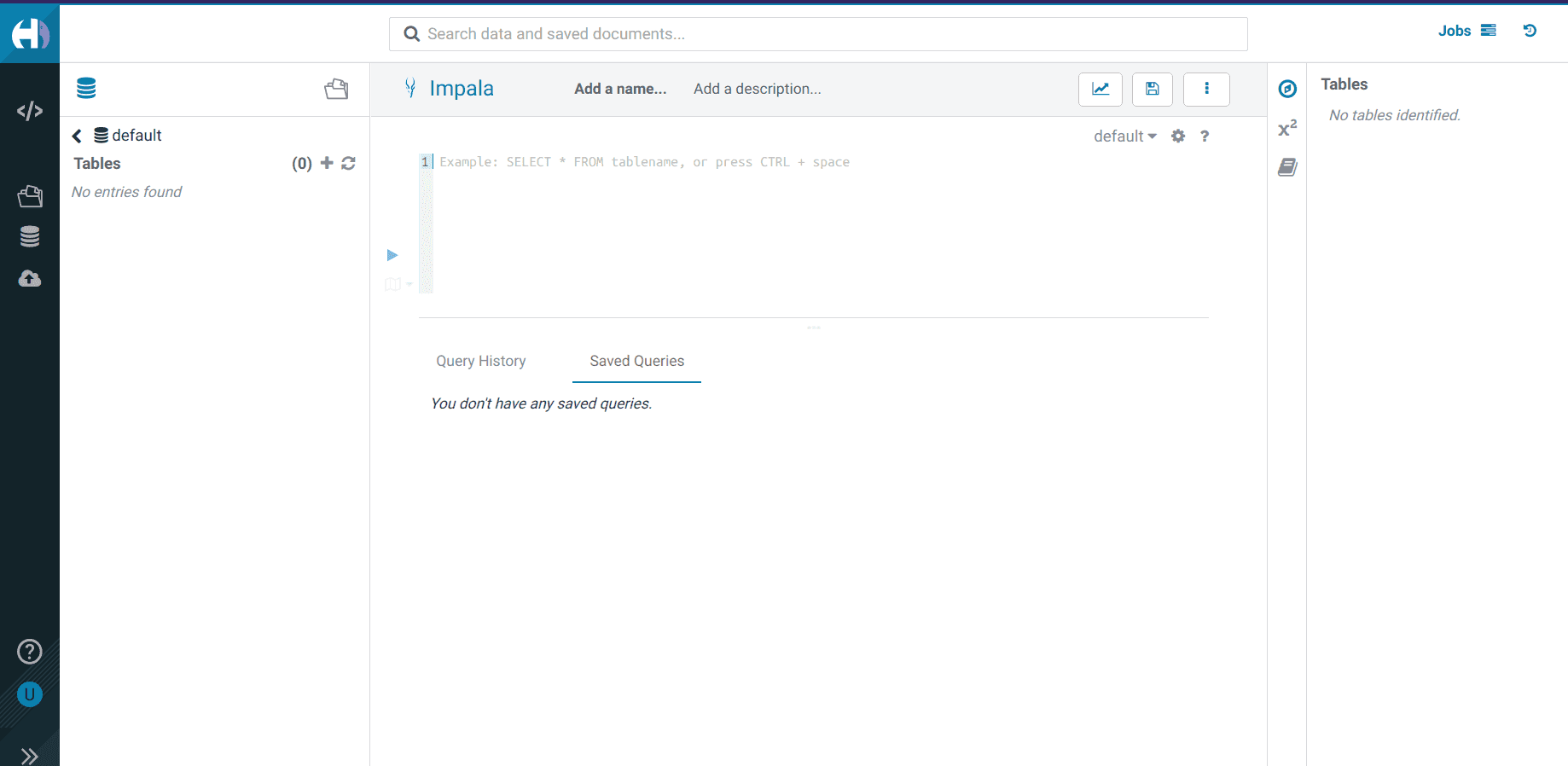
Information Warehouse
This service permits customers to create databases and tables and carry out queries on the info utilizing SQL. A warehouse holds knowledge prepared for evaluation, and the service features a Information Visualization characteristic. Customers have to allow the Information Warehouse service for his or her surroundings and create a so-called “digital knowledge warehouse” to deal with analytical workloads. These actions create Kubernetes clusters and a filesystem storage (EFS within the case of AWS) on the exterior cloud supplier.
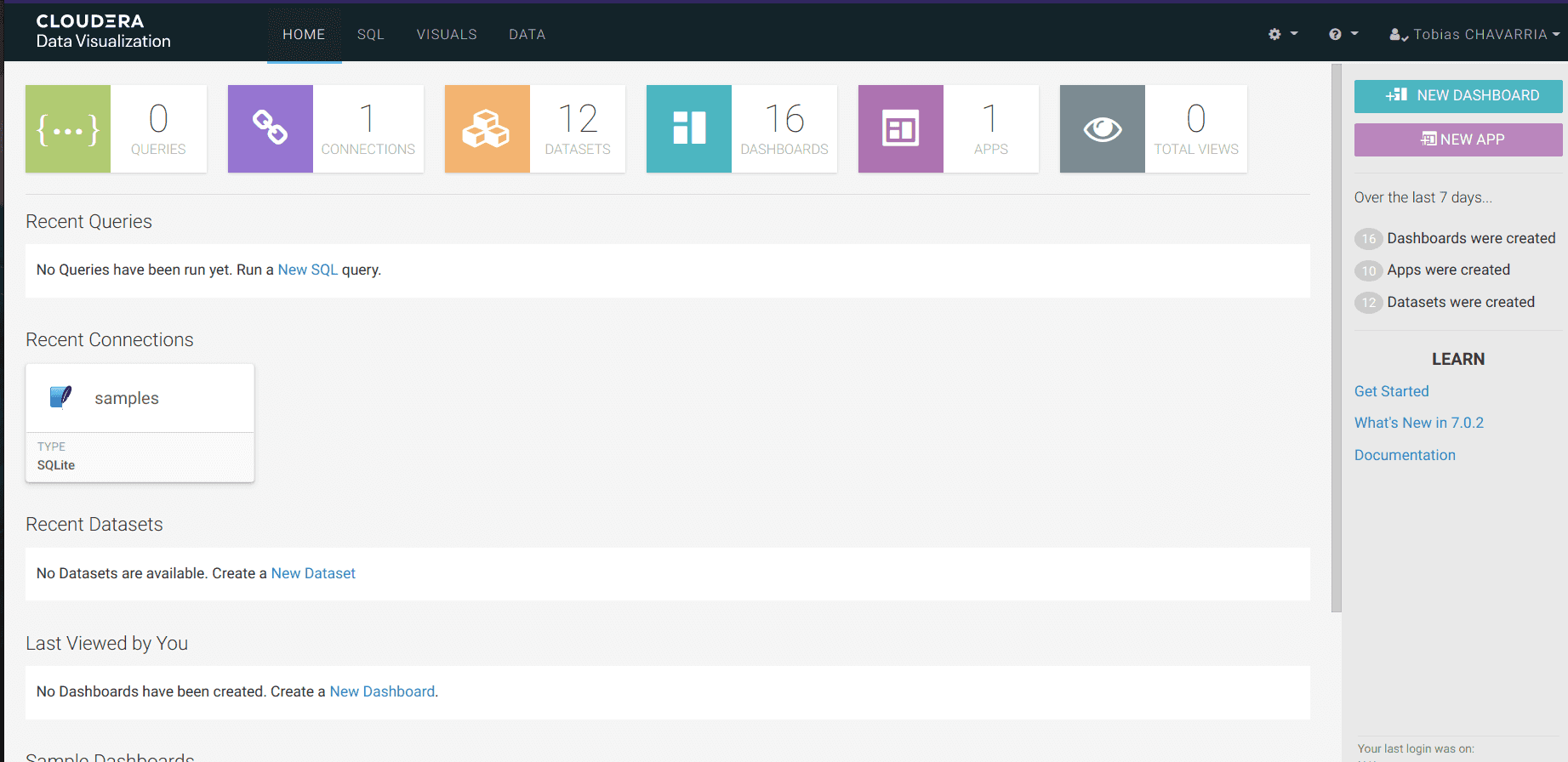
Operational Database
This service creates databases for dynamic knowledge operations and is optimized for on-line transactional processing (OLTP). This distinguishes it from the Information Warehouse service, which is optimized for on-line analytical processing (OLAP). Since we don’t want OLTP capabilities, we’re not going to make use of the Operational Database service, and so we received’t talk about it additional. You can see extra concerning the distinction between OLTP and OLAP processing in our article on the different file formats in big data and extra concerning the Operational Datastore within the official Cloudera documentation.
Machine Studying
CDP Machine Studying is the software utilized by knowledge scientists to carry out estimations, classifications and different AI-related duties. We’ve got no want for machine studying in our structure and due to this fact we’re not going into extra element on this service. For any further info seek advice from the Cloudera website.
Our Structure
Now that we’ve had a take a look at the providers provided by CDP, the next structure emerges:
-
Our CDP Public Cloud surroundings is hosted on AWS as that is at the moment the one possibility that helps Iceberg tables.
-
Information is ingested utilizing CDP DataFlow and saved in an information lake constructed on Amazon S3.
-
Information processing is dealt with by Spark jobs that run by way of the Information Engineering service.
-
Processed knowledge is loaded right into a Information Warehouse and in the end served by way of the built-in Information Visualization characteristic.
The following two articles configure the surroundings. Then, you’ll learn to handle customers and their permissions. Lastly, we create the info pipeline.
Comply with alongside: Stipulations
If you wish to observe alongside as we progress in our sequence and deploy our end-to-end structure your self, sure necessities should be met.
AWS useful resource wants and quotas
As described within the earlier sections, every CDP service provisions assets out of your exterior cloud supplier. For instance, working all of the required providers deploys a small fleet of EC2 cases with many digital CPUs throughout them.
In consequence, it is advisable take note of the service quota Customary Occasion Run on Demand (A, C, D, H, I, M, R, T, Z). This quota governs what number of digital CPUs chances are you’ll provision concurrently.
To confirm in case your quota is excessive sufficient and to extend it if obligatory, do the next in your AWS console:
- Navigate to the area the place you wish to create the assets
- Click on in your consumer title
- Click on on Service Quotas
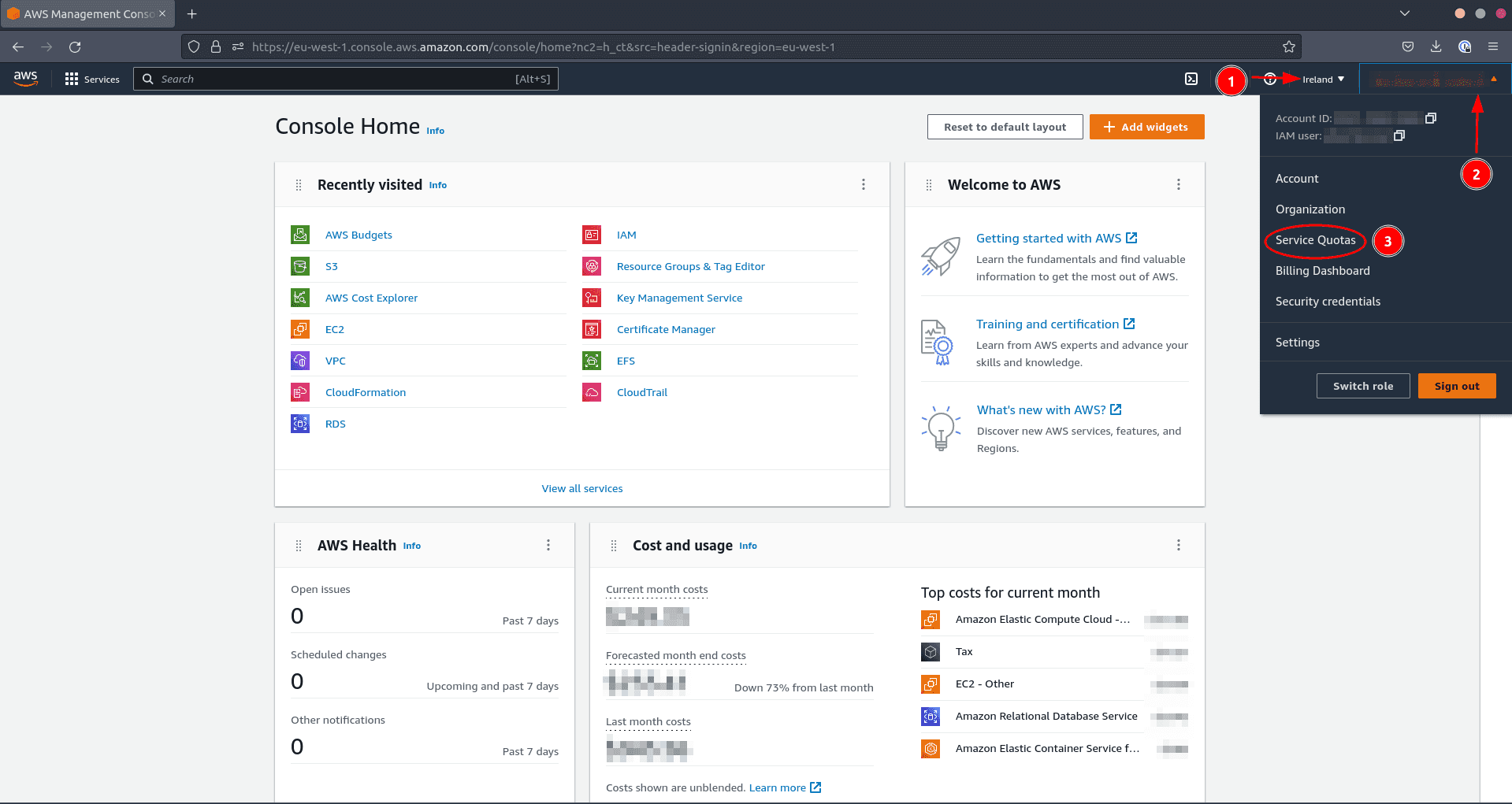
Now let’s take a look at the quotas for EC2
- Click on on Amazon Elastic Compute Cloud (Amazon EC2)
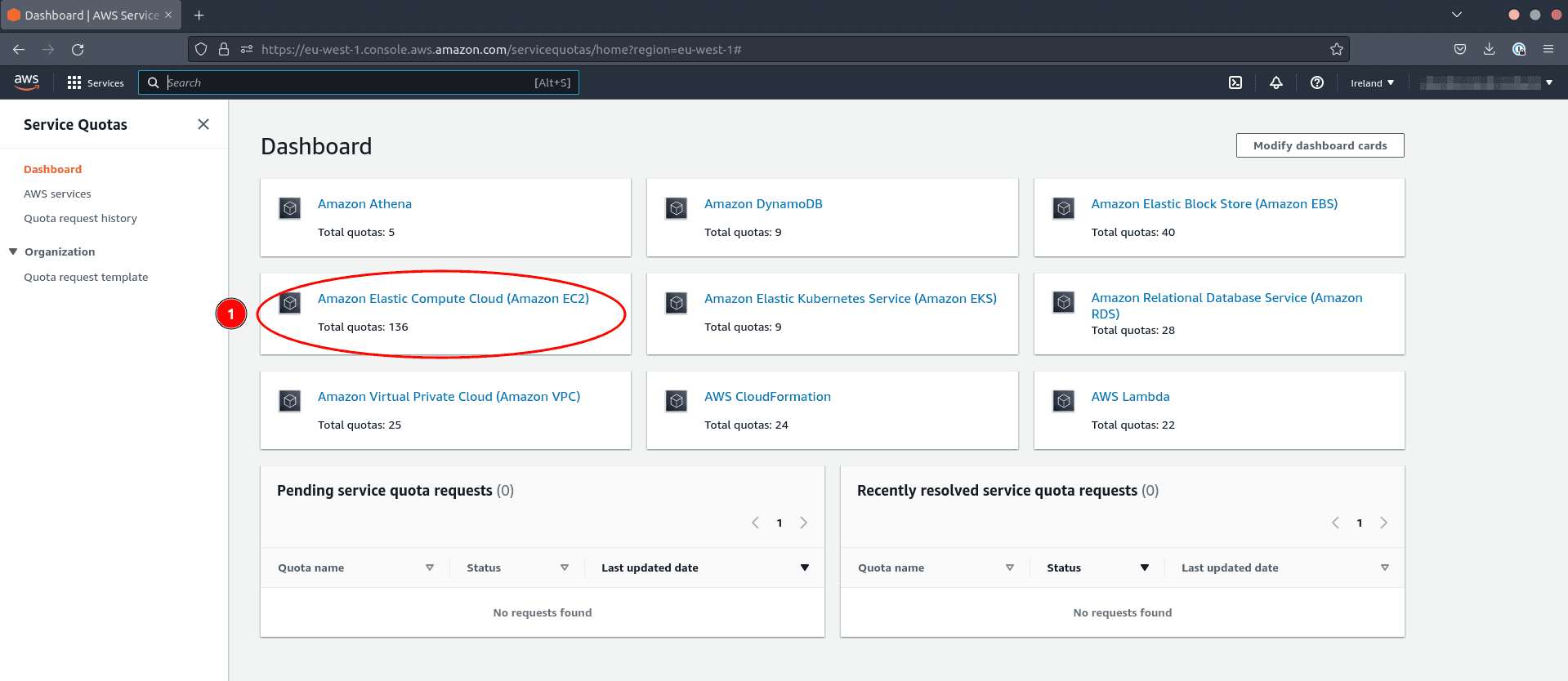
To examine the related quota limiting your vCPU utilization:
- Sort
Operating On-Demand Customary (A, C, D, H, I, M, R, T, Z) cases - Test that the variety of digital CPUs is over 300 to be protected
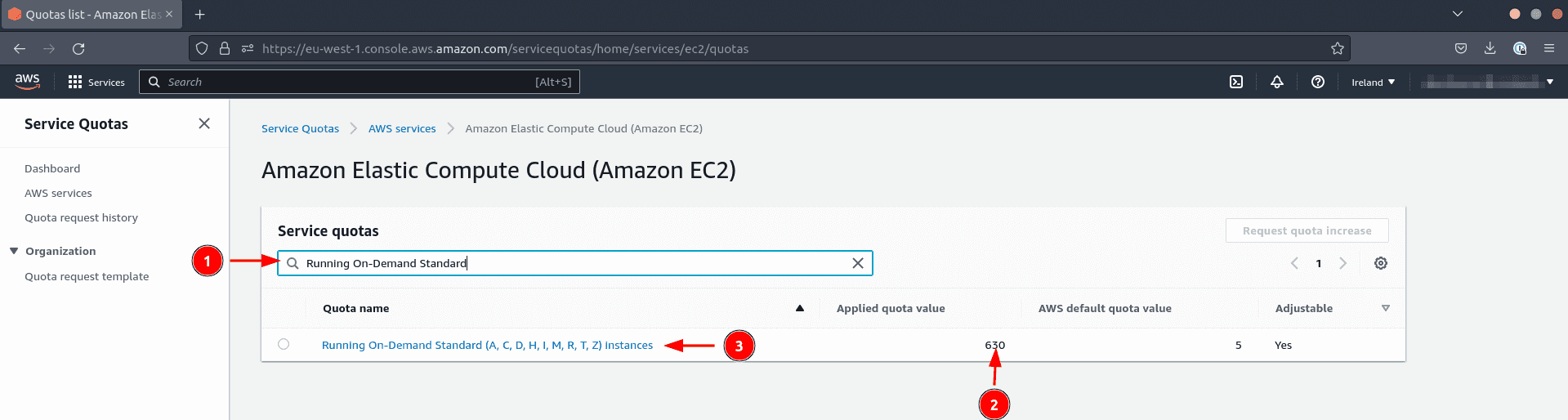
If the quota is just too restrictive, request a rise. This request can take greater than 24 hours to be granted.
- Click on on the title of the quota (motion 3 within the screenshot above)
- Click on on Request quota enhance to request a rise
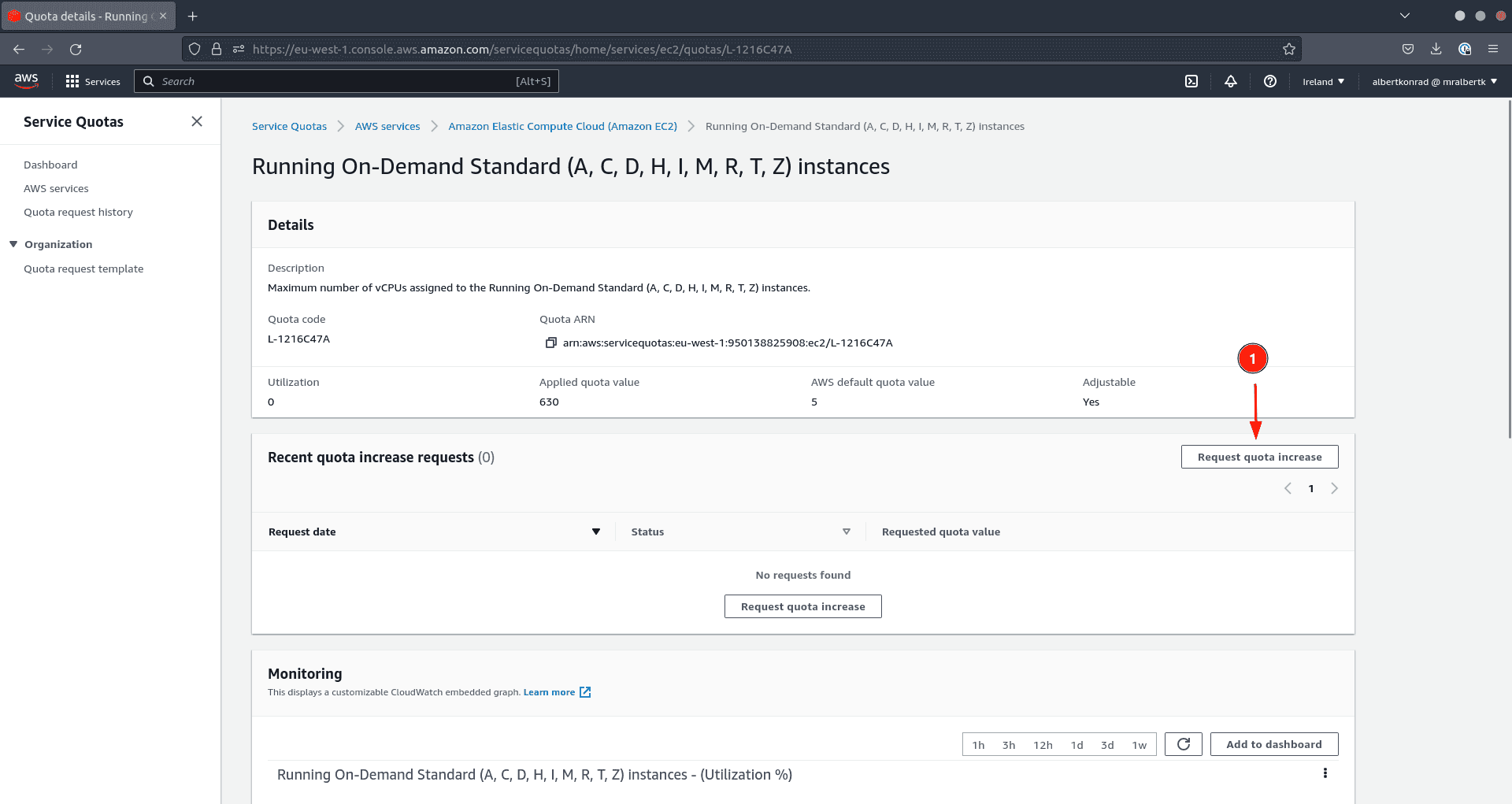
Different exterior cloud suppliers even have quotas for the creation of digital machines. If you end up in a state of affairs the place you wish to add CDP managed providers to an surroundings and the operation fails, it’s at all times price checking if quotas are the perpetrator.
Needless to say these quotas are set for funds safety causes. Utilizing extra assets will lead to the next invoice. Bear in mind that following the steps outlined on this sequence of articles will create assets in your AWS account, and these assets will incur some value for you. Everytime you follow with any cloud supplier, make sure you analysis these prices upfront, and to delete all assets as quickly as they’re not wanted.
AWS account permissions
You could have entry to an AWS consumer with not less than administrator entry to make the mandatory configurations for a CDP Public Cloud deployment. This consumer account can solely be configured by a consumer with root entry. Comply with the official AWS documentation to handle consumer permissions accordingly.
CDP account registration
You additionally have to have entry to a Cloudera license and a consumer account with not less than PowerUser privileges. In case your group has a Cloudera license, discuss to an administrator to acquire entry with the mandatory stage of privilege. Alternatively, you would possibly wish to take into account signing up for a CDP Public Cloud trial.
AWS and CDP command-line interfaces
In case you are not comfy with CLI instructions, the sequence additionally present all duties being carried out by way of the net interfaces supplied by Cloudera and AWS. That mentioned, you would possibly select to put in the AWS and CDP CLI instruments in your machine. These instruments assist you to deploy environments and to allow providers in a quicker and extra reproductible method.
Set up and configure the AWS CLI
The AWS cli set up is defined within the AWS documentation.
For those who occur to make use of NixOS or the Nix bundle supervisor, set up the AWS CLI by way of the Nix packages website.
To configure the AWS CLI, it is advisable retrieve the entry key and secret entry key of your account as defined within the AWS documentation. Then run the next command:
Present your entry key and secret entry key, the area the place you wish to create your assets, and make sure you choose json as Default output format. You are actually prepared to make use of AWS CLI instructions.
Set up and configure the CDP CLI
CDP CLI makes use of python 3.6 or later and requires pip to be put in in your system. The Cloudera documentation guides you thru the consumer set up course of to your working system.
For those who occur to make use of use NixOS or a Nix bundle supervisor, we advocate you to first set up the virtualenv bundle after which observe the steps for the Linux working system.
Run the next code to confirm that CLI is working:
As with the AWS CLI, the CDP CLI requires an entry key and a secret entry key. Log into the CDP Console to retrieve these. Observe that you just want the PowerUser or IAMUser function in CDP to carry out the duties beneath:
-
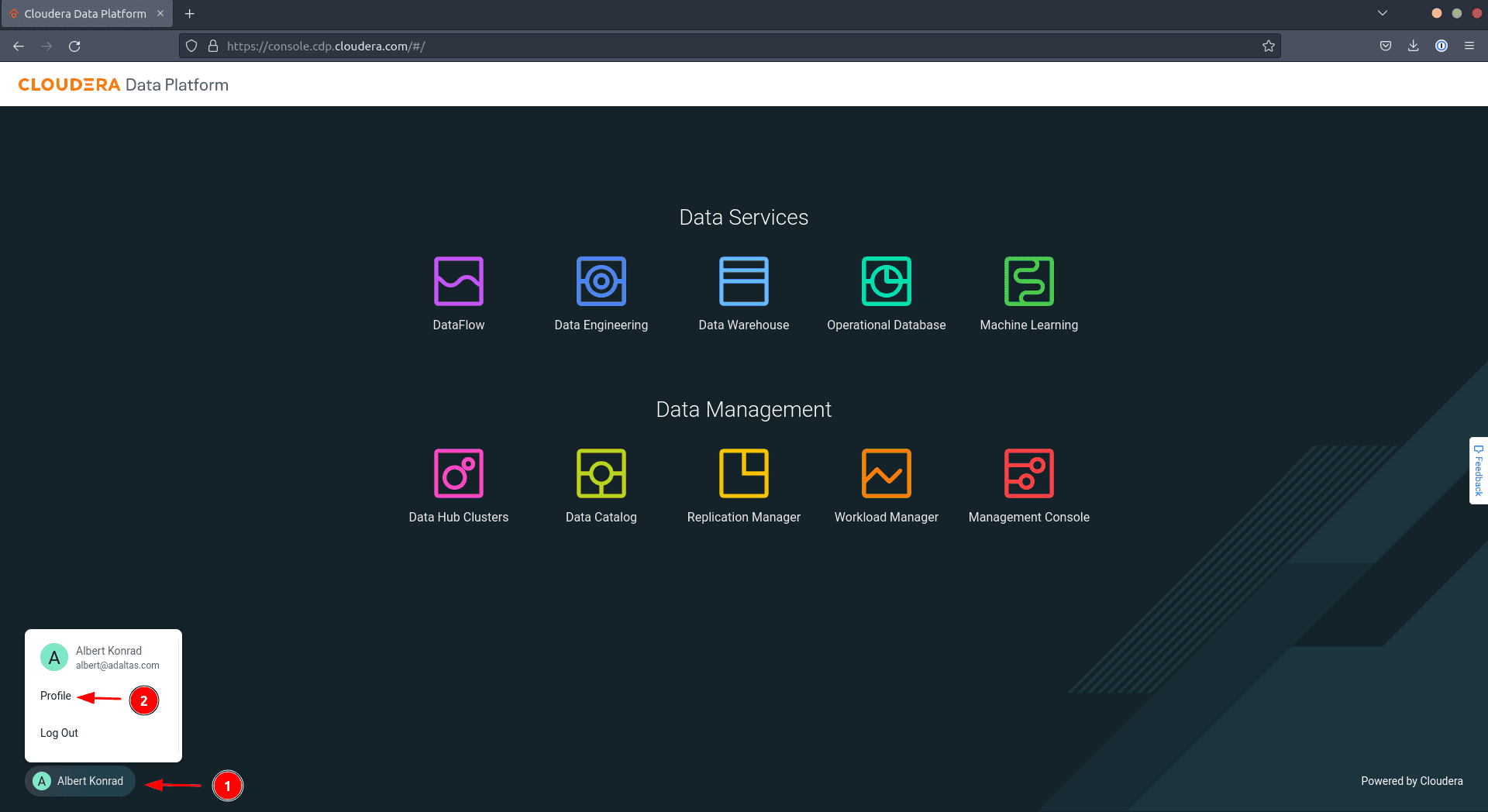
Click on in your consumer title within the backside left nook, then choose Profile
-
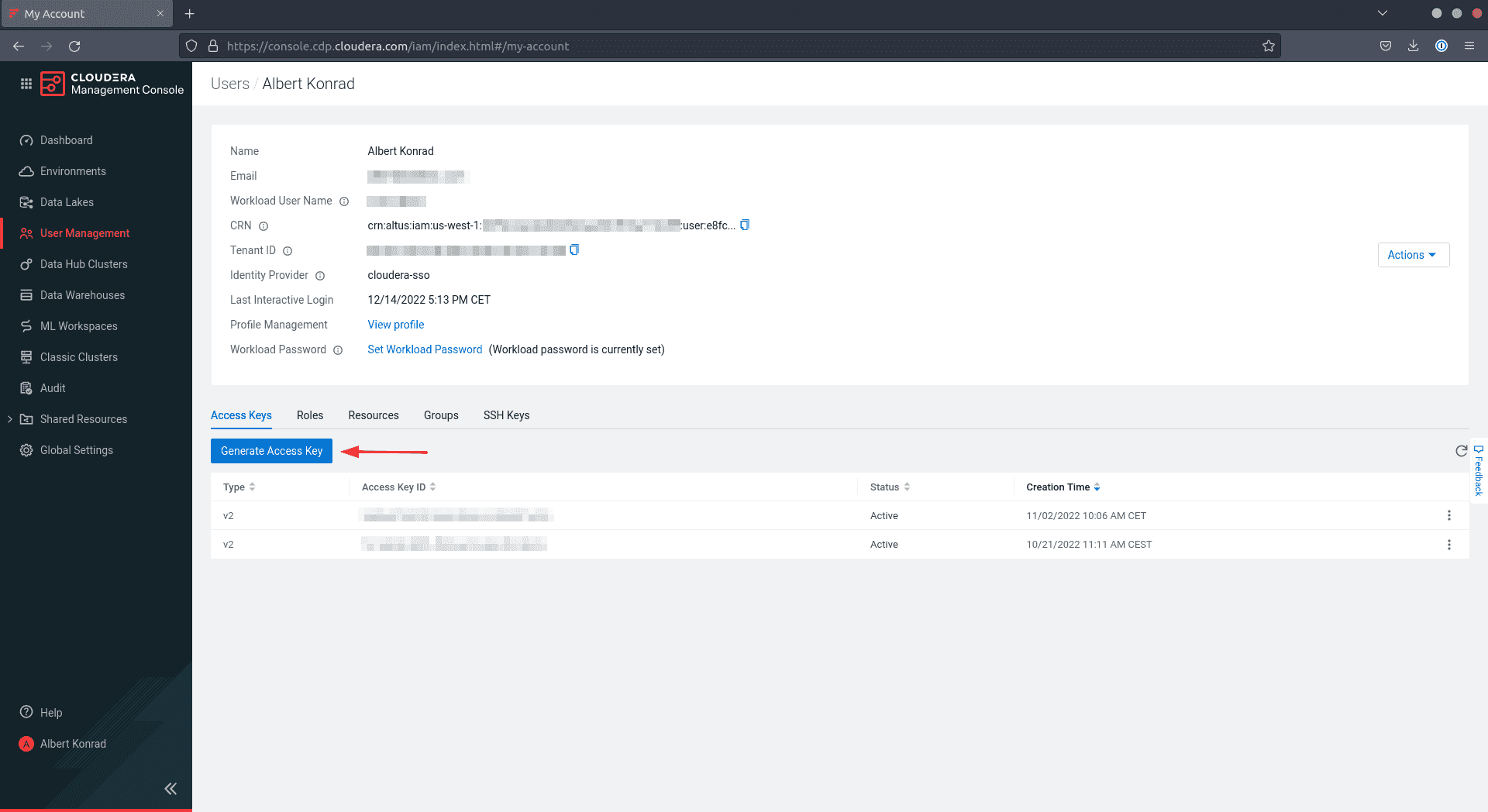
On the Entry Keys tab, click on on Generate Entry Key
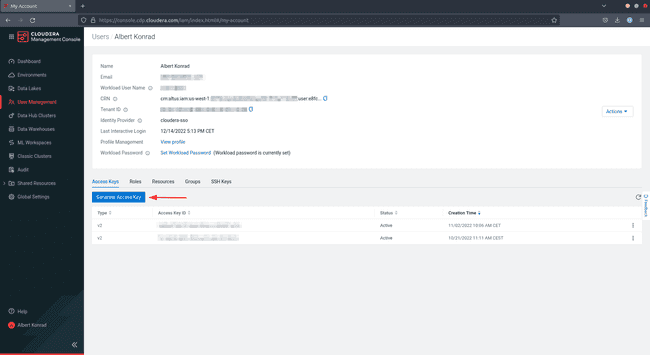
-
CDP creates and shows the knowledge on the display. Now both obtain and save the credentials in
~/.cdp/credentialslisting or run the commandcdp configurewhich creates the file for you.
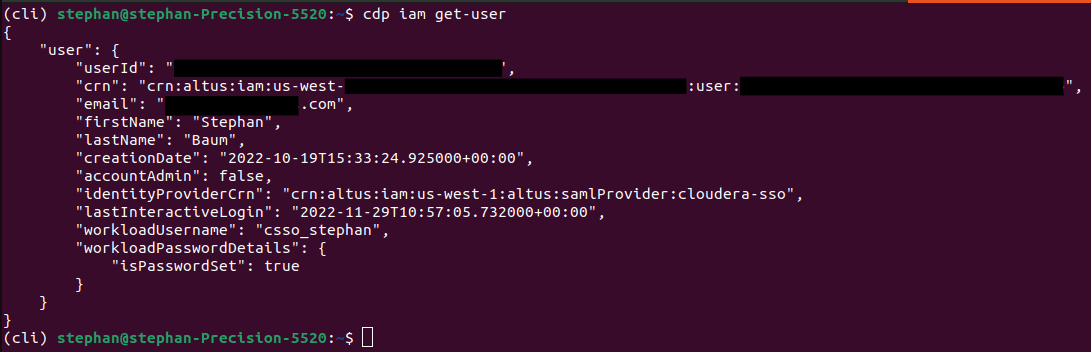
To verify success run the next code. You must get an analogous output as proven beneath:
Now that all the pieces is about up you might be able to observe alongside! Within the subsequent chapter of this sequence, we’re going to deploy a CDP Public Cloud surroundings on AWS.