LLM’s rise and efficiency requirement
Lately, a big language mannequin (LLM) similar to GPT, Lama, and misunderstanding has influenced the understanding and breeding of pure language. Nonetheless, an essential problem within the deployment of those fashions lies in enhancing their efficiency, particularly for lengthy textual content -related duties. There’s a highly effective method to cope with this problem okEy-Worth Catching (KV Money).
On this article, we’ll spotlight how KV catching works, its function within the focus methodology, and the way it will increase the efficiency in LLM.
How one can develop massive fashions of language
We have to begin with the fundamentals of performing on the token technology of the token technology really, within the LLM.
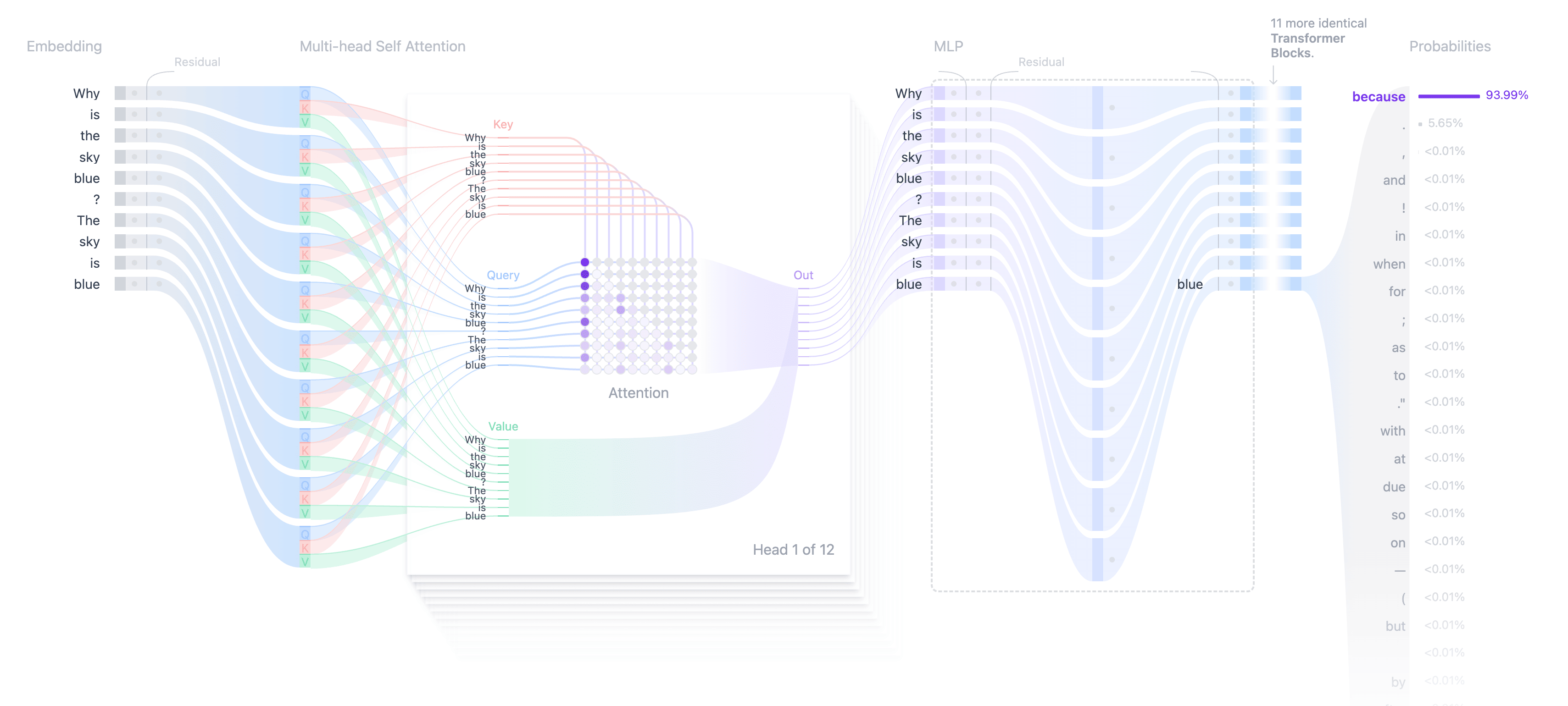
Step 1: Tokinization
Earlier than a mannequin acts on a sentence, it breaks it into small items known as tokens.
For instance phrase: Why is the sky blue?
Token depends upon the used toothenzer, token phrases, sub -words, and even letters can symbolize the characters.
For simplicity, assume that the phrase has been tuned:('Why', 'is', 'the', 'sky', 'blue', '?')
Every token is assigned a novel ID, which is fashioned a sequence similar to:(1001, 1012, 2031, 3021, 4532, 63)
Step 2: To embed
Token ID is mapped in excessive -dimensional vectors, known as embedid, utilizing an embedded embedding matrix.
Instance:
- Token “Why” (ID: 1001) → Vector:
(-0.12, 0.33, 0.88, ...) - Token is “ID: 1012) → Vector:
(0.11, -0.45, 0.67, ...)
This sentence is then represented as a sequence of vectors embedded:(Embedding("Why"), Embedding("is"), Embedding("the"), ...)
Step 3: Make the token with consideration
Uncooked -embed Context. For instance, the that means of “sky” is completely different in phrases “Why is the sky blue?” And “the sky is clear at the moment.” So as to add context, the LLM use the main target methodology.
How focus works: (keys, questions and values)
The eye methodology makes use of three substances:
- Query (Q). The present tokens represents the embedded, which is modified by means of a realized weight matrix. It determines how a lot consideration is paid to different tokens in continuity.
- Key (of). Details about every token (together with earlier individuals) is modified by means of the realized weight matrix. It’s used to match comparability with the question (Q).
- Worth (v). Represents the unique content material of the token, and supplies info that focuses on the rating -based mannequin “recuperate”.
Instance: Let’s take into account the motion on the phrase for instance, and the present token is “given”.
Whenever you take motion on the token “Di”, the mannequin shares all of the processed token (“why,”, “” “) all of the processed token (” why, “” “) utilizing their key (ok) and worth (v) –
Query for (Q) ““::
The vector for “D” has been derived by making use of the burden matrix realized on its embedded:Q("the") = WQ ⋅ Embedding("the")
Keys (of) and values (v) for earlier token:
Each earlier token produces:
- Key (of):
Okay("why") = WK ⋅ Embedding("why") - Worth (v):
V("why") = Embedding("why")
Calculation of consideration
The mannequin calculates comparability by evaluating Q (“why”, “is”, “and” The “) utilizing a dot product.
In consequence, the scores are made as ordinary with the tender Max to rely the burden of the eye.
These weights apply to related Wei vectors to replace the “Di” context.
In abstract:
- Q (D). The “The” embedded the “The” embedded a realized weight matrix passes by means of WQ All For the token “The”. This inquiry is used to find out how a lot consideration ought to be given to different tokens.
- Okay (why). The embedded “Why,” passes by means of a realized weight matrix WK in order that the important thing vector Okay may be created for “why”. This secret’s in comparison with Q (The) for counting consideration.
- V (why). The embedded “Why,” creates a “vector v” why passing by means of a realized matrix WV. This worth is useful in updating the context of “Di” based mostly on the burden of its focus in comparison with Q (The D).
Step 4: Updating the configuration
Every token embedded is up to date based mostly on all different tokens. This course of repeats the layers of consideration, by which every layer improves the understanding of context.
Step 5: Creating subsequent token (taking samples)
As soon as the embassies get context in all layers, Mannequin Output A Posts Vector – A uncooked rating distribution on phrases for every token place.
La The Textual content Era La, the mannequin is concentrated on the login for the final place. The login is transformed into prospects utilizing the tender Max perform.
Methods to take sampling
- Taking grasping samples. More than likely chooses the token (within the image talked about, it makes use of grasping samples and chooses “as a result of”).
- Taking the top-samples of. Selects the random between the higher ok Potential tokens.
- Taking temperature samples. Adjusts the potential distribution to beat random pin (similar to, excessive temperature = extra random selection).
How does the important thing worth assist assist
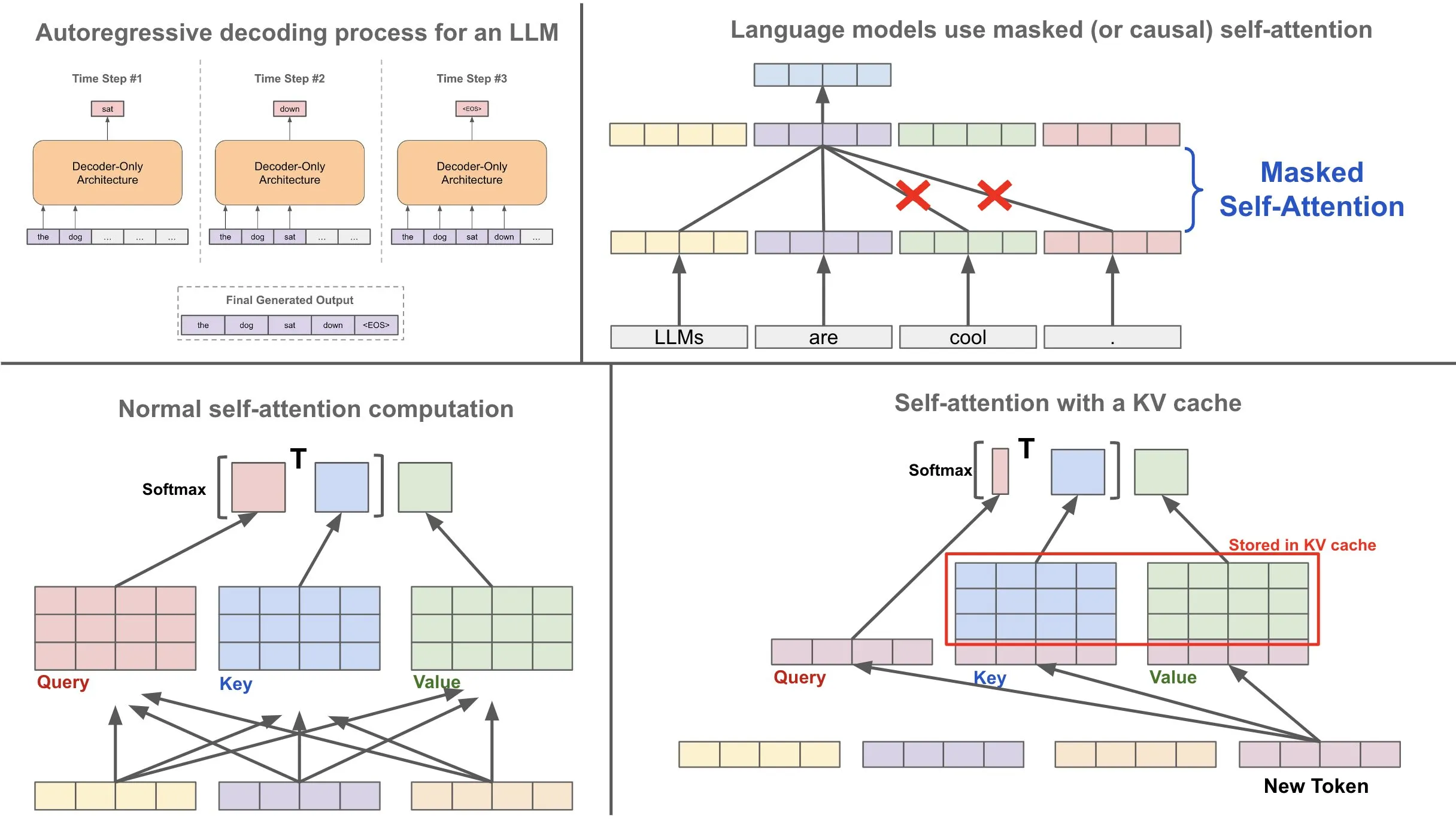
With out the KV cache
At every technology section, the mannequin restores the keys and values for all tokens within the sequence, even is already processed. This resulted in a sq. computational value (O (N3)), the place N is the variety of tokens, which makes it ineffective for an extended setting.
With a ok v cache
The mannequin shops the keys and values for the primary processing token in reminiscence. Whenever you produce a brand new token, it reuses ketchy keys and values, and counts solely the important thing, worth and queries for the brand new token. This correction considerably reduces the necessity for restoration of the substances for full continuity, which improves each computational time and reminiscence use.
Code with KV cache
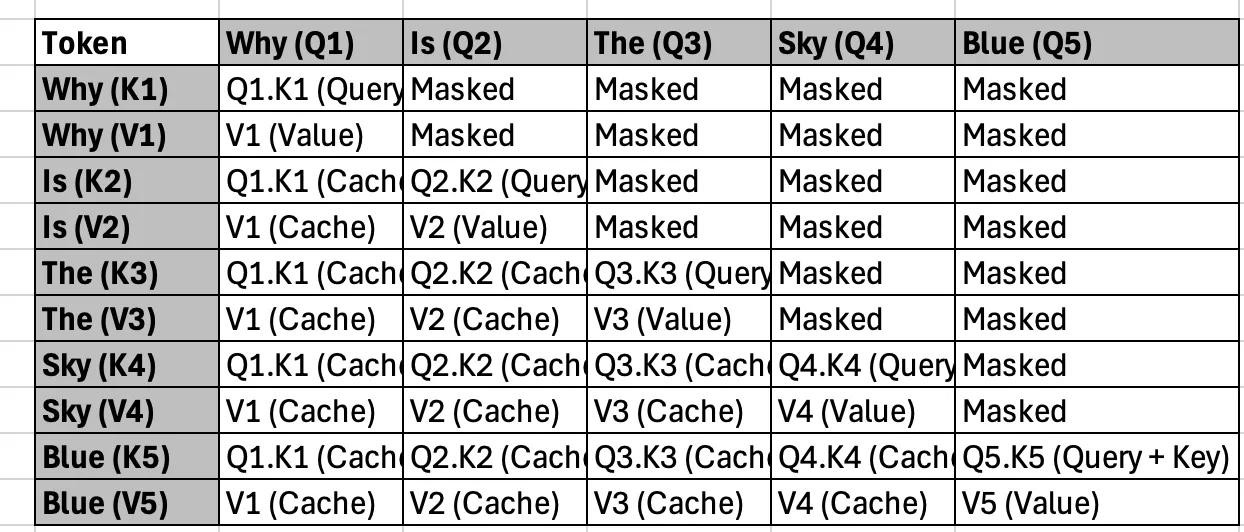
Suppose the mannequin has already developed this format “Why is the sky?” The keys and values of those token are saved in money. Whenever you put together the following token, “blue”:
- The mannequin retrieves ketchard keys and values for the token “Why,” “” “” “,” and “Sky”.
- It counts the queries, the important thing and the worth for “blue” and calculates the eye utilizing the queries for “Blue” with ketchy keys and values.
- Case for future use features a new counting key and worth for “blue”.
import torch
import time
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load tokenizer and mannequin
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.2-1B")
mannequin = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3.2-1B")
# Transfer mannequin to the suitable system
system = torch.system("cuda" if torch.cuda.is_available() else "cpu")
mannequin.to(system)
# Enter textual content
input_text = "Why is the sky blue?"
input_ids = tokenizer.encode(input_text, return_tensors="pt").to(system)
def generate_tokens(use_cache, steps=100):
"""
Operate to generate tokens with or with out caching.
Args:
use_cache (bool): Whether or not to allow cache reuse.
steps (int): Variety of new tokens to generate.
Returns:
generated_text (str): The generated textual content.
length (float): Time taken for technology.
"""
past_key_values = None # Initialize previous key values
input_ids_local = input_ids # Begin with preliminary enter
generated_tokens = tokenizer.decode(input_ids_local(0)).cut up()
start_time = time.time()
for step in vary(steps):
outputs = mannequin(
input_ids=input_ids_local,
use_cache=use_cache,
past_key_values=past_key_values,
)
logits = outputs.logits
past_key_values = outputs.past_key_values if use_cache else None # Cache for subsequent iteration
# Get the following token (argmax over logits)
next_token_id = torch.argmax(logits(:, -1, :), dim=-1)
# Decode and append the brand new token
new_token = tokenizer.decode(next_token_id.squeeze().cpu().numpy())
generated_tokens.append(new_token)
# Replace enter IDs for subsequent step
if use_cache:
input_ids_local = next_token_id.unsqueeze(0) # Solely the brand new token for cached mode
else:
input_ids_local = torch.cat((input_ids_local, next_token_id.unsqueeze(0)), dim=1)
end_time = time.time()
length = end_time - start_time
generated_text = " ".be a part of(generated_tokens)
return generated_text, length
# Measure time with and with out cache
steps_to_generate = 200 # Variety of tokens to generate
print("Producing tokens WITHOUT cache...")
output_no_cache, time_no_cache = generate_tokens(use_cache=False, steps=steps_to_generate)
print(f"Output with out cache: {output_no_cache}")
print(f"Time taken with out cache: {time_no_cache:.2f} secondsn")
print("Producing tokens WITH cache...")
output_with_cache, time_with_cache = generate_tokens(use_cache=True, steps=steps_to_generate)
print(f"Output with cache: {output_with_cache}")
print(f"Time taken with cache: {time_with_cache:.2f} secondsn")
# Evaluate time distinction
time_diff = time_no_cache - time_with_cache
print(f"Time distinction (cache vs no cache): {time_diff:.2f} seconds")When is Key Catching probably the most environment friendly?
The advantages of KV cache rely upon a number of elements:
- Mannequin measurement. Massive fashions (eg, 7b, 13b) carry out extra computations per token, so catching saves extra time.
- The size of continuity. KVC Money Lengthy Lengthy Lonely Lonely Lonely Lonely Lonely Lonely Lonely Lengthy Lonely Lonely Lonely Lengthy lengthy -lasting lengthy elements.
- {Hardware}. Because of parallel counting, GPUC advantages greater than catching than CCPUs.
Extends in KV cache: Fast catching
Whereas KV caches enhance the technology of textual content by reusing the keys and values for a pre -made token, PRomepat Catching The enter goes a step additional by concentrating on the steady nature of the immediate. Let’s discover out what’s fast and it’s important.
What’s a fast catching?
Included Immediate Catching Pre -contesting and storing the keys and values for the enter immediate Earlier than the technology course of begins. Because the enter immediate doesn’t change throughout the textual content basic, its keys and values stay everlasting and may be reused successfully.
Why instantly caught the instances?
Immediate catching affords separate advantages in landscapes with massive indicators or repeated use of the identical enter:
- Keep away from the ineffective rely. With out a fast catching, the mannequin produces keys and values for the enter immediate each time to the token. This results in pointless computational overheads.
- Fixed the technology. As soon as making ready these values, the fast catching course of considerably accelerates the method, particularly the lengthy enter gestures, or when many completion are produced.
- Higher for batch processing. Speedy catching is invaluable in instances the place the identical indicator is reused in quite a few bachelor’s functions or minor variations, which ensures everlasting efficiency.
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load mannequin and tokenizer
model_name = "mistralai/Mistral-7B-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
mannequin = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype=torch.float16)
assistant_prompt = "You're a useful and educated assistant. Reply the next query thoughtfully:n"
# Tokenize the assistant immediate
input_ids = tokenizer(assistant_prompt, return_tensors="pt").to(mannequin.system)
# Step 1: Cache Keys and Values for the assistant immediate
with torch.no_grad():
start_time = time.time()
outputs = mannequin(input_ids=input_ids.input_ids, use_cache=True)
past_key_values = outputs.past_key_values # Cache KV pairs for the assistant immediate
prompt_cache_time = time.time() - start_time
print(f"Immediate cached in {prompt_cache_time:.2f} secondsn")
# Operate to generate responses for separate questions
def generate_response(query, past_key_values):
question_prompt = f"Query: {query}nAnswer:"
question_ids = tokenizer(question_prompt, return_tensors="pt").to(mannequin.system)
# Append query tokens after assistant cached tokens
input_ids_combined = torch.cat((input_ids.input_ids, question_ids.input_ids), dim=-1)
generated_ids = input_ids_combined # Initialize with immediate + query
num_new_tokens = 50 # Variety of tokens to generate
with torch.no_grad():
for _ in vary(num_new_tokens):
outputs = mannequin(input_ids=generated_ids, past_key_values=past_key_values, use_cache=True)
next_token_id = outputs.logits(:, -1).argmax(dim=-1).unsqueeze(0) # Choose subsequent token
generated_ids = torch.cat((generated_ids, next_token_id), dim=-1) # Append subsequent token
past_key_values = outputs.past_key_values # Replace KV cache
response = tokenizer.decode(generated_ids(0), skip_special_tokens=True)
return response, past_key_values
# Step 2: Go a number of questions
questions = (
"Why is the sky blue?",
"What causes rain?",
"Why can we see stars at night time?"
)
# Generate solutions for every query
for i, query in enumerate(questions, 1):
start_time = time.time()
response, past_key_values = generate_response(query, past_key_values)
response_time = time.time() - start_time
print(f"Query {i}: {query}")
print(f"Generated Response: {response.cut up('Reply:')(-1).strip()}")
print(f"Time taken: {response_time:.2f} secondsn")For instance:
- Buyer Assist Boats. The system indicator doesn’t usually change for each person’s interplay. Immediate catching boot permits the static system to successfully react with out restoration of indicators and values.
- Era of artistic content material. When a number of completions are produced from the identical enter immediate, numerous random (similar to temperature settings) may be utilized when reusing money keys and values for the enter.
Conclusion
The important thing worth performs an essential function in enhancing the efficiency of LLM. Previous to reusing calculated keys and values, computational overheads are decreased, accelerates breed, and improves effectivity, particularly lengthy layouts and huge fashions.
The implementation of KV catching is crucial for actual -world functions similar to summary, translation, and dialogue methods, allows LLM to successfully measure and supply quick, extra dependable outcomes. Mixed with methods similar to immediate catching, KV cache ensures that LLM can deal with difficult and useful resource -related duties with higher efficiency.
I hope you’ll find this text helpful, and if you happen to do, take into account giving clap.