Giant language fashions like GPT, Claude, Llama, and others have the potential to rework community operations. We’re conversant in how they assist us generate code, summarize texts, and reply fundamental questions, however till not too long ago their utility to community operations has been suspect. Nonetheless, it was only a matter of time till we understood the use-cases and learn how to mitigate among the preliminary issues like hallucinations and knowledge privateness.
I imagine there are two essential use-cases proper now, with a 3rd proper across the nook. First, LLMs can question giant and numerous datasets of community telemetry quicker than any engineer, which in flip reduces decision time and will increase community efficiency and reliability. Second, as half of a bigger workflow, LLMs may help us carry out superior evaluation on community telemetry thereby offering larger perception and understanding of what’s in any other case a fancy net of assorted telemetry knowledge. And within the close to future, agentic AI, which is admittedly an extension of my second use case, will assist us automate duties and extra autonomously handle community operations.
On this submit we’ll focus on the primary two use-cases and contact on the third. We’ll additionally unpack among the limitations we face implementing LLMs in NetOps, and we’ll focus on a number of fast and simple methods to get began proper now.
Probabilistic Fashions
In the beginning, take into account that LLMs are primarily based on probabilistic fashions. Probabilistic fashions are a sort of mathematical mannequin used to foretell the following merchandise in a sequence, corresponding to the following phrase in a sentence. That is primarily based on the concept that the following phrase in a sequence might be approximated (predicted) by all of the previous phrases.

Nonetheless, although LLMs are technically probabilistic, they use the Transformer mannequin which is far more subtle than a strict probabilistic mannequin like an n-gram. Transformers, which do use probabilistic strategies, depend on a complicated structure of encoding and decoding in addition to an consideration mechanism to grasp context.
Nonetheless, LLMs actually don’t have any “intelligence” as we perceive it (some consultants disagree), which implies that although their outputs might be spectacular, there’s room for error. Due to this fact, after we use an LLM in our NetOps workflow, we have to make use of strategies to make responses related to our particular area in addition to scale back errors.
Community Operations Use Instances
The primary use-case I discussed within the introduction is each sensible and a better option to get began in comparison with superior evaluation and constructing autonomous techniques.
The primary sensible use for LLMs in NetOps is to make the method of interrogating very giant, numerous, and divergent community datasets a lot, a lot simpler and quicker.
In trendy community operations, we’re amassing logs, metrics, flows, and fairly a little bit of metadata about every of those units individually and the site visitors traversing them. Querying this knowledge simply, rapidly, in real-time, and at scale, is a big endeavor.
Now add to this knowledge all the configuration information, open tickets, closed tickets, inner KB articles, community diagrams, and all the seller paperwork for the units in your racks and closets. That’s an enormous quantity of further knowledge, each in quantity and sort. And although it’s a unique sort of information (largely textual content) from system and site visitors info, it’s nonetheless essential for NetOps.
This can be a huge drawback. Sadly, and despite advances with community automation, mining via all of that knowledge remains to be largely a handbook course of primarily based on our instinct and the domain-specific data tucked away in our brains. I imply, as engineers we nonetheless plow through it, but it surely takes hours, days, or weeks of clue-chaining, pouring over logs, and numerous Zoom calls. LLMs may help.
One instance is prompting an LLM in pure language to run a question for you. As an example, you can immediate the system to point out you all community site visitors egressing US-EAST-1 within the final 24 hours heading to embargoed nations. The output may very well be in human readable textual content, or in case you construction your workflow correctly, it may reply with a visualization.
One other instance is a degree 1 NOC engineer engaged on a ticket for a sluggish community. The engineer can ask the LLM in pure language if there are any units with community issues. This can be a broad query, and it assumes the LLM even is aware of what “community issues” means. Correctly designed, an LLM in a NetOps agentic AI workflow can generate a response that the interface on an inner swap connecting to the SD-WAN edge system is dropping packets, however not fairly sufficient to set off an alert.
In my hypothetical state of affairs, I envision the community engineer as a degree 1 NOC engineer who could not know the instructions to entry these units, or they could not have sufficient expertise to even consider checking interface stats within the first place. As a result of the LLM permits us to make use of pure language to question a big dataset, we lower the method of intuitive and handbook clue chaining and scale back the imply time to decision for this incident. LLMs make accessing, filtering, and querying knowledge dramatically simpler and quicker, in addition to democratize info amongst anybody who can enter a immediate into the LLM.
Utilizing pure language to simply and rapidly question large datasets is nice, however what about extra superior queries that contain evaluation or inference?
A second sensible use case for LLMs in NetOps is superior knowledge evaluation.
Properly, this isn’t precisely true. LLMs aren’t designed and optimized for advanced statistical evaluation on new knowledge (regression, correlation calculation, time-series forecasting, and so on). They aren’t meant for real-time telemetry processing, both.
Nonetheless, if we use an LLM because the interface to work together with a RAG system the place knowledge processing is already carried out, or maybe a workflow of AI brokers designed to do this type of evaluation, then we simply made superior community telemetry knowledge evaluation dramatically simpler to do – utilizing the LLM as our person interface.
For instance, we will immediate the LLM with a query that requires some type of inference. As a result of the LLM understands language and due to this fact the character of what we’re asking, it could actually create the related python script or SQL question, or maybe name the suitable device (agent) to orchestrate an information evaluation workflow.
The LLM doesn’t do the evaluation, but it surely’s an unimaginable device to facilitate the evaluation workflow and report again the ends in a human readable format. This use-case requires cautious planning and design by way of LLM routing, knowledge processing and storage, learn how to deal with real-time telemetry, and so forth, but it surely’s one other very sensible use-case for augmenting an engineer working manufacturing networks.
The third use-case for LLMs in NetOps is because the orchestrator for an agentic AI system that autonomously manages community operations.
2024 is usually known as the 12 months of AI brokers, and I imagine that’s for good motive. There’s a lot potential to make use of an LLM on this means. For NetOps, the LLM turns into our person interface to a fancy system of brokers that search, apply ML fashions, resolve which instruments to make use of to realize a aim, and so forth. I’ve seen community orchestration platforms come and go through the years, however I’m wondering if agentic AI will lastly get us nearer to the dream of a self-operating community.
In any case, let’s now deal with learn how to get began implementing an LLM for the primary two use-cases (I develop upon brokers a bit of extra later and can go a lot deeper in a unique weblog submit).
Implementing LLMs in a Community Operations Workflow
Implementing an LLM in a NetOps workflow is extra advanced than merely asking ChatGPT to generate a config snippet (though that’s positively helpful). There are numerous components to think about corresponding to price, knowledge administration, mitigating hallucinations, and dealing with real-time telemetry.
Hallucinations, for instance, are sometimes the deal-breaker for engineers. From a excessive degree, hallucinations are factually incorrect responses attributable to imperfect coaching knowledge and a scarcity of real-world grounding. This implies we have to make use of numerous strategies to make sure the responses we get are related and correct.
Additionally, LLMs aren’t well-suited for real-time telemetry processing. There’s latency in producing responses, a scarcity of steady studying capabilities, and so forth. So one other consideration is how we ingest, course of, and make obtainable real-time knowledge from our community.
Clearly there are some issues to think about, however don’t let that cease you from attempting. There are some fast and comparatively straightforward methods we will get began proper now. I’ll begin with the simplest and least expensive technique and make my means progressively to essentially the most tough, costly, and arguably the best.
1. Embody the Related Information in Your Immediate
First, the LLM must know in regards to the knowledge we care about, which might be in an inner database the mannequin wasn’t skilled on. A simple means to do that is to incorporate the info you wish to question in your precise immediate. That may very well be actually copying and pasting a physique of uncooked circulate logs, SNMP knowledge, syslog messages, system configuration information, and so forth proper into your immediate, then asking the LLM to summarize them or discover some sample, and so on.
That is efficient, however you’re restricted by the variety of obtainable tokens within the mannequin’s context window, or in different phrases, what number of characters you possibly can enter. For a lot of fashions this might be someplace round 32,000 tokens, although some fashions are releasing variations with very giant context home windows. For instance, GPT-4o has a 128k context window and Claude 2.1 has a 200k token context window. In keeping with latest analysis, nevertheless, there’s a transparent distinction between most context size and efficient context size, to not point out that even a 200k context window quantities to solely round 500 pages of textual content.
So for many fashions, this implies you possibly can’t embrace all the info about your community within the immediate. Positively some tables and smaller databases, however not the sum whole of all of your logs, telemetry, documentation, tickets, and so forth. Methods like summarization and filtering may help, although it’s best to nonetheless watch out with filling up a 200k token context window due to lengthy context points like “misplaced within the center.”
For a lot of circumstances, although, that is a simple, low cost, and efficient means to make use of an LLM in your NetOps workflow proper now. Simply keep in mind that this technique received’t work for doing something subtle like predictive evaluation.
Some sensible makes use of for this technique are summarizing syslog messages, figuring out associated occasions in a log file, or reviewing code for you that you simply embrace in your immediate. Efficient, however restricted to solely the info within the immediate. Now let’s transfer on to strategies to question your community telemetry databases.
2. Use an LLM to Generate a Question over Tabular Information
We are able to use the LLM to translate pure language to a question over tabular knowledge you probably have already got or at the least can put together comparatively simply.
For instance, you should utilize an LLM to generate a human readable immediate to a python script that runs a pandas operation, executes towards a dataframe, the results of which the LLM can interpret and return in a human-readable format.
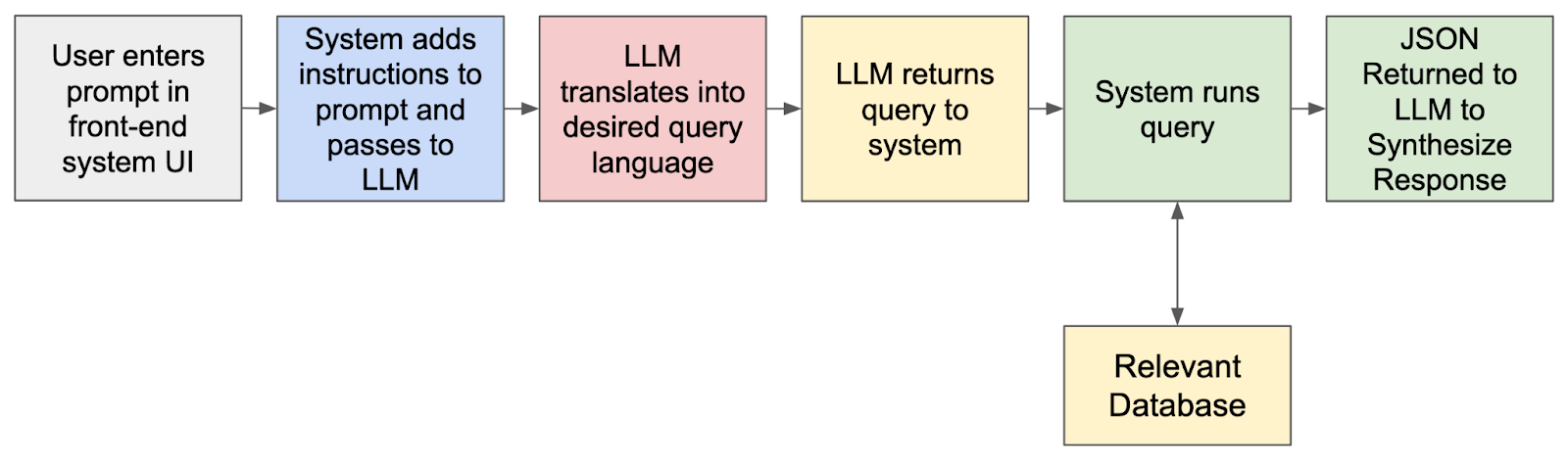
The simplified workflow seems to be like this:

You may as well use the LLM to translate an engineer’s immediate to SQL. For instance, you possibly can enter a pure language question corresponding to “present me all community site visitors from the final week the place the bandwidth exceeded 1 Gbps.” The LLM interprets this into an SQL question and routes the question to the related database for you.
This workflow seems to be just about like this:

To do that programmatically (as an alternative of simply utilizing the LLM as a coding assistant), we will use a easy net front-end that takes your pure language immediate, augments the enter behind the scenes with a template of directions for the LLM to create a sure sort of question, like in SQL as the instance above, and return the ends in a sure format, corresponding to JSON.
With that returned JSON output, you will get again human-readable textual content or generate a visualization. The facility right here is making operating queries extraordinarily quick and simple utilizing pure language. Your staff can create very advanced queries with no need to know learn how to code, you possibly can restrict the entry to the info primarily based on position, and you may current the outcomes to the engineer in a means that makes essentially the most sense.
In fact it is a very excessive degree overview and assumes the kind of knowledge / database you’ve gotten lends itself to this technique. In manufacturing, this may be extra advanced and will embrace a caching part that permits you to append your earlier prompts. This can be a nice option to make the most of an LLM in a short time within the real-world and with actual outcomes with out having to construct a RAG system with a vector database, which we’ll discuss subsequent.
3. Retrieval-Augmented Technology (RAG) with a Vector Database
One other technique is to make use of a RAG system with a vector database. RAG (retrieval-augmented technology) is a workflow wherein we level an LLM to an exterior database in order that the LLM is proscribed to solely the info we care about and insert related context knowledge into the immediate to tighten the LLMs capacity to reply. This doesn’t at all times must be a vector database in that we will retrieve knowledge and enrich a response with no vector database. However on this part I’d prefer to deal with this very fashionable and efficient option to make utilizing an LLM related to your particular data area or group and scale back hallucinations.
It’s necessary to grasp that RAG is the mechanism the LLM makes use of to answer your immediate, not carry out knowledge evaluation. Neither does it put together your exterior database in any means. In order it seems, utilizing RAG is sort of as a lot an train in knowledge administration and processing as it’s augmenting an LLM.
Based mostly on what form and the way a lot knowledge we’re coping with, we choose the suitable embedding mannequin to rework our knowledge (in our case community telemetry, logs, configurations, and so on) into embeddings, after which choose essentially the most applicable vector database (like Pinecone, Milvus, or Chroma) to retailer these embeddings.
The LLM is then programmed to reply prompts solely within the context of this new database, type of like an open e book check. In different phrases, after we enter a immediate, the LLM augments its response by retrieving the info for the reply from solely the info we inform it to make use of, thus producing a extra correct response.
This is a superb means to make use of LLMs in many various industries, particularly if the exterior database is especially text-based. If we’re speaking about numerous knowledge varieties, as is the case with the networking business, that is extra advanced than simply pointing an LLM to an exterior database. And there are some limitations to RAG, particularly for community operations, together with retrieval not at all times being contextually correct.
The excessive degree workflow could be very easy:
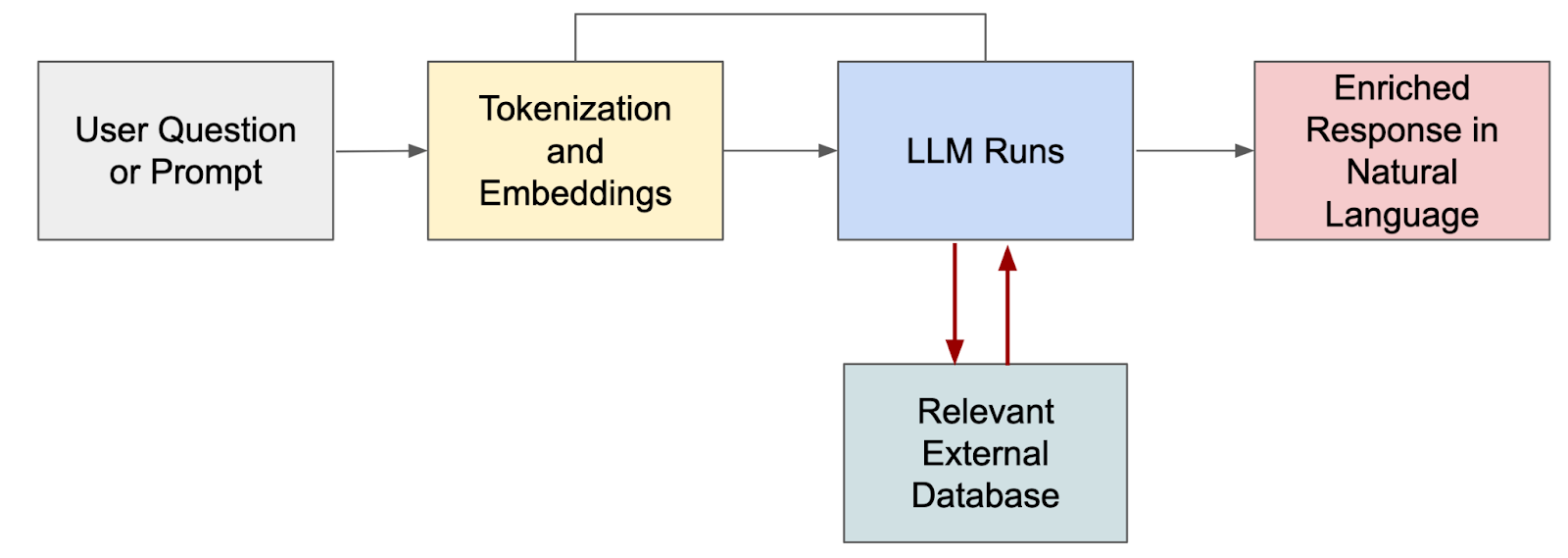
The enriched response we see on the fitting is the LLM responding to the immediate utilizing the info within the RAG database. This implies we will restrict the LLM to answer the info we care about like our database of circulate logs, metrics, configurations, tickets, and so forth. There are numerous methods to perform this, too. For instance, the vector database could also be looked for related paperwork previous to the immediate going to the LLM, wherein case the LLM receives the immediate together with the contextually related info to synthesize its response.
A good way to start out with RAG in NetOps is to make use of it for asking pure language questions towards a knowledgebase, log assortment, or ticketing system. Begin with textual content knowledge in only one database and experiment with learn how to get the outcomes you need. It will get extra difficult when coping with a number of varieties of community telemetry, particularly real-time knowledge, so contemplate beginning with a extra easy chatbot on your inner kb.
For instance, a simple implementation for an AI chatbot with out having to get into coping with real-time telemetry knowledge may very well be a chat interface on your ticketing system. You should use pure language to open, replace, create, and seek for tickets simply and rapidly.
4. Agentic AI
This can be a extra advanced technique for utilizing an LLM in NetOps, however one which I imagine will change the way in which we run networks. In an AI workflow of impartial AI brokers, an LLM would act as an orchestrator that interprets prompts and outcomes, routes duties to brokers, and probably assists brokers in device calling to work together with exterior techniques, enabling them to take actions and retrieve knowledge. On this workflow, the LLM is a crucial a part of an general system.
Within the graphic under you possibly can see that the LLM interacts with different AI brokers which may very well be net searches, different databases, ML fashions, and so forth. In observe, the LLM would probably resolve primarily based on a semantic understanding of the immediate which agent it will ahead to subsequent.
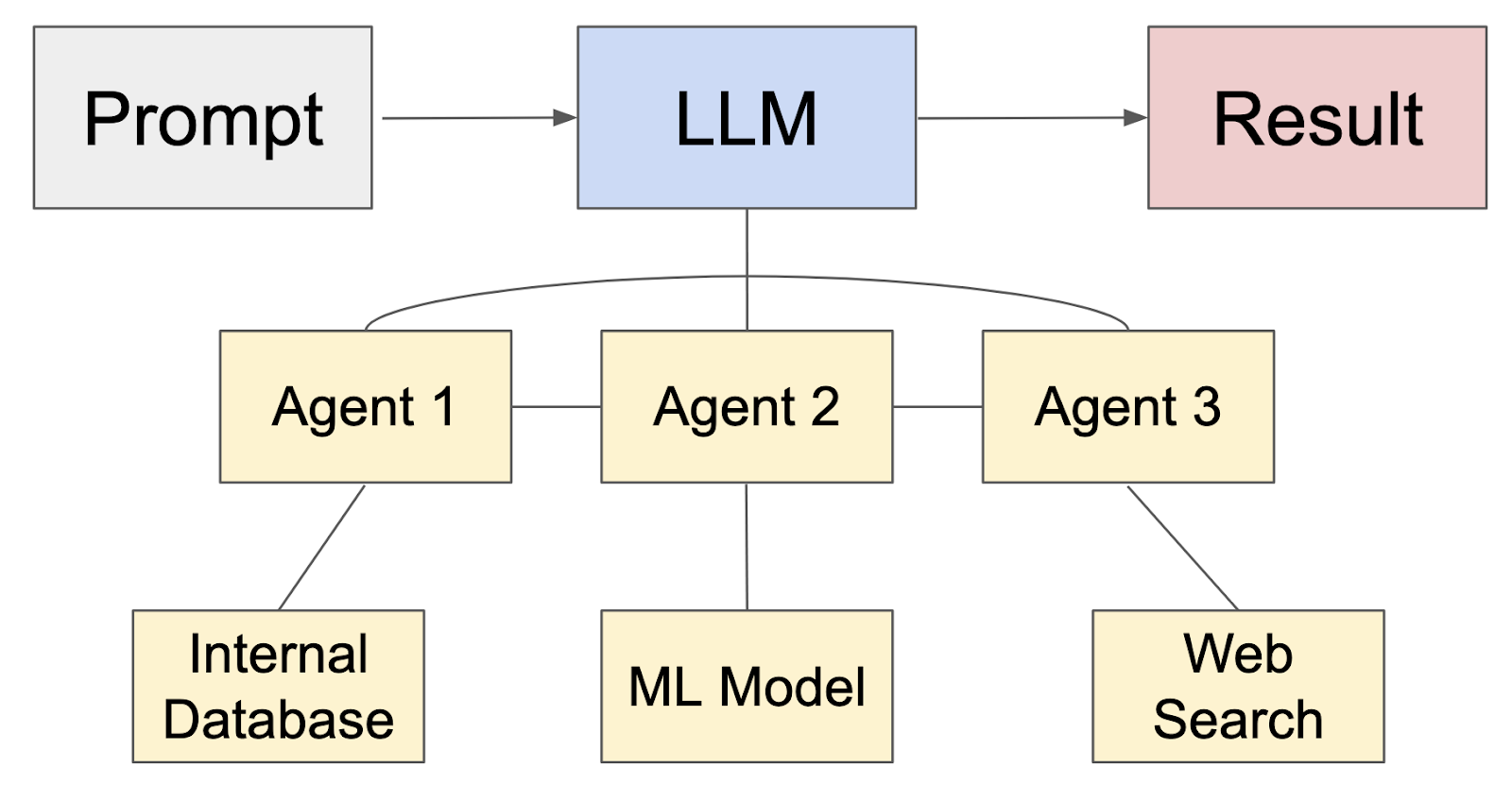
I imagine we’ll see plenty of worth to our business as we develop agentic AI techniques with LLM orchestrators. I do know we’ve had numerous community orchestrators and guarantees of automated remediation for years, however I imagine making use of agentic AI to NetOps has a really actual potential to revolutionize the IT business.
5. Wonderful-tuning and Retrieval-Augmented Wonderful Tuning
Wonderful-tuning a mannequin is mostly costly, time-consuming, and infrequently requires your personal GPUs. Wonderful-tuning provides further knowledge to the pre-trained mannequin (like community area knowledge) in order that the mannequin’s parameters might be adjusted and it could actually reply precisely about what you care about.
Although that is completely doable with smaller fashions, strategies like LoRA, and rented GPUs like Azure AI Studio, that is far more tough and costly to do with foundational fashions like GPT and with real-time telemetry.
Retrieval-Augmented Wonderful Tuning, or RAFT was developed very not too long ago (June 2024) to mix the advantages of fine-tuning with RAG to make fine-tuning simpler and cheaper and RAG simpler. RAFT is one thing we will use at present to make LLMs extra correct, and due to this fact simpler in a NetOps workflow. However this technique is costlier and sophisticated to implement than RAG alone or utilizing an LLM to generate your queries, and I nonetheless foresee an issue dealing with real-time knowledge.
Nonetheless, fine-tuning and RAFT is one other means to enhance the relevance and accuracy of responses of LLMs such that they’re extra helpful for question and inference of numerous community knowledge.
Getting Began
All of that being mentioned, I do suppose that many people in community operations are nonetheless attempting to essentially nail down the long run worth and the way we will really implement LLMs into our workflow. Immediately, towards the top of 2024, I believe we’re in place to start out experimenting with expertise and adopting it into our NetOps workflows. I believe a serious problem, although, might be to determine learn how to do it with the very distinctive, numerous, and real-time knowledge we’ve in networking.
Regardless of these challenges, I imagine there’s worth in incorporating an LLM in your NetOps workflow proper now, and these strategies may help you get there. This isn’t an all-or-nothing proposition, both. Experiment with a pilot undertaking to question just one sort of static inner knowledge (even when it’s pretend), like per week of system metrics from some switches.
Then strive completely different strategies to make use of an open small scale LLMs like Llama to question it. Construct a RAG system for textual content knowledge solely, and use free instruments like Ollama, Langchain, Llama, Milvus, Pinecone, Chroma, and perhaps a free embedding mannequin off the Huggingface web site. There are a ton of free instruments on the market and simply as many weblog posts from people constructing this out for their very own domains.
Right here’s a quick-start course of I’m engaged on (I’m on step 2):
- Experiment with querying a small, static dataset of logs or tickets utilizing an open-source LLM like Llama
- Construct a fundamental RAG system utilizing text-based inner KBs and free vector databases like Pinecone or Chroma.
- Experiment with agentic AI by organising a easy orchestrator that triggers alerts primarily based on LLM output.
- Experiment with fine-tuning a small mannequin like Mistral 7B (or something very small) utilizing a comparatively small dataset. You are able to do that proper in your laptop computer if it’s first rate, or you should utilize a service like Azure AI Studio.
Thanks,
Phil