In response to the 2016 Ponemon Institute analysis, the typical downtime price is almost $9,000 per minute. These downtimes not solely price cash, but additionally harm the aggressive edge and model fame. The group can put together for downtime by figuring out the basis causes. For that, they want data on how the software program and infrastructure is operating. Many software program applications assist mixture this data, and one of many standard and most used instruments is Loki.
Nevertheless, holding Loki energetic beneath strain is one other downside. Just lately, our group ran the only monolith occasion of Loki as a personal logging resolution for our utility microservices quite than for observing Kubernetes clusters. The logs had been saved within the EBS filesystem. We needed our system to be extra sturdy and resilient, so we applied Excessive Availability (HA) and Catastrophe Restoration (DR) for our microservice utility.
However it was tough because of the following causes:
- Operating clustered Loki will not be doable with the file system retailer until the file system is shared in some vogue (NFS, for instance)
- Utilizing shared file programs with Loki can result in instability
- Shared file programs are susceptible to a number of points, together with inconsistent efficiency, locking issues, and elevated danger of knowledge corruption, particularly beneath excessive load
- Sturdiness of the information relies upon solely on the file system’s reliability, which might be unpredictable
Our group determined to make use of object shops like S3 or GCS. Object shops are particularly engineered for prime sturdiness and supply superior behind-the-scenes mechanisms — resembling computerized replication, versioning, and redundancy — to make sure your information stays secure and constant, even within the face of failures or surges.
On this weblog submit, we’ll share how we achieved excessive availability (HA) and configured catastrophe restoration (DR) for Loki with AWS S3 as our object retailer. This ensures we are able to forestall or decrease information loss and enterprise disruption from catastrophic occasions. First, let’s briefly talk about Loki and see what makes it completely different.
What Is Loki, and How Does It Assist With Observability?
Loki is a horizontally-scalable, highly-available, multi-tenant log aggregation system impressed by Prometheus. Loki differs from Prometheus by specializing in logs as an alternative of metrics, and accumulating logs through push, as an alternative of pull. It’s designed to be very cost-effective and extremely scalable. Not like different logging programs, Loki doesn’t index the contents of the logs however solely indexes metadata about your logs as a set of labels for every log stream.
A log stream is a set of logs that share the identical labels. Labels assist Loki to discover a log stream inside your information retailer, so having a top quality set of labels is vital to environment friendly question execution.
Log information is then compressed and saved in chunks in an object retailer resembling Amazon Easy Storage Service (S3) or Google Cloud Storage (GCS) or, for improvement or proof of idea, on the file system. A small index and extremely compressed chunks simplify the operation and considerably decrease Loki’s price. Now, we are able to perceive the Loki deployment modes.
Loki Deployment Modes
Loki is a distributed system composed of a number of microservices, every accountable for particular duties. These microservices might be deployed independently or collectively in a novel construct mode the place all companies coexist throughout the identical binary. Understanding the accessible deployment modes helps you determine easy methods to construction these microservices to attain optimum efficiency, scalability, and resilience in your surroundings. Totally different modes will influence how Loki’s parts — just like the Distributor, Ingester, Querier, and others — work together and the way effectively they handle logs.
The listing of Loki microservices consists of:
- Cache Technology Loader
- Compactor
- Distributor
- Index-Gateway
- Ingester
- Ingester-Querier
- Overrides Exporter
- Querier
- Question-Frontend
- Question-Scheduler
- Ruler
- Desk Supervisor (deprecated)
Totally different Deployment Modes
Loki provides completely different deployment modes, which permit us to construct a extremely accessible logging system. We have to select the modes contemplating our log reads/writes price, upkeep overhead, and complexity. Loki might be deployed in three modes, every fitted to various scales and complexity.
Monolithic Mode
The monolithic mode is the only choice, the place all Loki’s microservices run inside a single binary or Docker picture beneath all targets. The goal flag is used to specify which microservices will run on startup. This mode is good for getting began with Loki, as it may possibly deal with log volumes of as much as roughly 20 GB/day. Excessive availability might be achieved by operating a number of cases of the monolithic setup.
Easy Scalable Deployment (SSD) Mode
The Easy Scalable Deployment (SSD) mode is the popular mode for many installations and is the default configuration when putting in Loki through Helm charts. This mode balances simplicity and scalability by separating the execution paths into distinct targets: READ, WRITE, and BACKEND. These targets might be scaled independently primarily based on enterprise wants, permitting this deployment to deal with up to some terabytes of logs per day. The SSD mode requires a reverse proxy, resembling Nginx, to route consumer API requests to the suitable learn or write nodes, and this setup is included by default within the Loki Helm chart.
Microservices Deployment Mode
The microservices deployment mode is essentially the most granular and scalable choice, the place every Loki part runs as a separate course of specified by particular person targets. Whereas this mode provides the best management over scaling and cluster administration, it is usually essentially the most advanced to configure and keep. Subsequently, microservices mode is really helpful just for enormous Loki clusters or operators requiring exact management over the infrastructure.
Attaining Excessive Availability (HA) in Loki
To attain HA in Loki, we’d:
- Configure a number of Loki cases utilizing the
memberlist_configconfiguration - Use a shared object retailer for logs, resembling:
- AWS S3
- Google Cloud Storage
- Any self-hosted storage
- Set the
replication_factorto three
These steps assist guarantee your logging service stays resilient and responsive.
Memberlist Config
memberlist_config is a key configuration ingredient for reaching excessive availability in distributed programs like Loki. It permits the invention and communication between a number of Loki cases, permitting them to kind a cluster. This configuration is important for synchronizing the state of the ingesters and making certain they will share details about information writes, which helps keep consistency throughout your logging system.
In a high-availability setup, memberlist_config facilitates the dynamic administration of cases, permitting the system to reply to failures and keep service continuity. Different components contributing to excessive availability embrace quorum, Write-Forward Log (WAL), and replication issue.
Replication Issue, Quorum, and Write-Forward Log (WAL)
1. Replication Issue
Usually set to three, the replication issue ensures that information is written to a number of ingesters (servers), stopping information loss throughout restarts or failures. Having a number of copies of the identical information will increase redundancy and reliability in your logging system.
2. Quorum
With a replication issue of three, at the very least 2 out of three writes should succeed to keep away from errors. This implies the system can tolerate the lack of one ingester with out dropping any information. If two ingesters fail, nonetheless, the system won’t be able to course of writes efficiently, thus emphasizing the significance of getting a enough variety of energetic ingesters to keep up availability.
3. Write-Forward Log (WAL)
The Write-Forward Log gives a further layer of safety towards information loss by logging incoming writes to disk. This mechanism is enabled by default and ensures that even when an ingester crashes, the information might be recovered from the WAL. The mix of replication and WAL is essential for sustaining information integrity, because it ensures that your information stays constant and retrievable, even within the face of part failures.
We selected the Easy Scalable Deployment (SSD) mode because the default deployment technique for operating Loki as an alternative of utilizing a number of cases in monolithic mode for prime availability. The SSD mode strikes a steadiness between ease of use and the power to scale independently, making it a really perfect alternative for our wants. Moreover, we opted to make use of AWS S3 as the article retailer whereas operating our utility and Loki in AWS EKS companies, which gives a sturdy and dependable infrastructure for our logging wants.
To streamline the setup course of, confer with the Terraform instance code snippet to create the required AWS assets, resembling IAM roles, insurance policies, and an S3 bucket with acceptable bucket insurance policies. This code helps automate the provisioning of the mandatory infrastructure, making certain that you’ve a constant and repeatable surroundings for operating Loki with excessive availability.
Information to Putting in Loki
Following the information, you’ll be able to set up Loki in Easy Scalable mode with AWS S3 as the article retailer. Under are the Helm chart values for reference, which you’ll customise primarily based in your necessities.
# https://github.com/grafana/loki/blob/primary/manufacturing/helm/loki/values.yaml
# Grafana loki parameters: https://grafana.com/docs/loki/newest/configure/
loki:
storage_config:
# utilizing tsdb as an alternative of boltdb
tsdb_shipper:
active_index_directory: /var/loki/tsdb-shipper-active
cache_location: /var/loki/tsdb-shipper-cache
cache_ttl: 72h # Could be elevated for quicker efficiency over longer question intervals, makes use of extra disk area
shared_store: s3
schemaConfig:
configs:
- from: 2020-10-24
retailer: tsdb
object_store: s3
schema: v12
index:
prefix: index_
interval: 24h
commonConfig:
path_prefix: /var/loki
replication_factor: 3
ring:
kvstore:
retailer: memberlist
storage:
bucketNames:
chunks: aws-s3-bucket-name
ruler: aws-s3-bucket-name
sort: s3
s3:
# endpoint is required if we're utilizing aws IAM consumer secret entry id and key to hook up with s3
# endpoint: "s3.amazonaws.com"
# Area of the bucketTo make sure the Loki pods are within the Operating state, use the command kubectl get pods—n loki.
On this setup, we’re operating a number of replicas of Loki learn, write, and backend pods.
With a replication_factor of three, it’s crucial to make sure that each the write and backend are working with three replicas; in any other case, the quorum will fail, and Loki can be unavailable.
The next picture illustrates Loki’s integration with Amazon S3 for log storage in a single-tenant surroundings. On this configuration, logs are organized into two main folders throughout the S3 bucket: index and faux.
- Index folder. This folder comprises the index recordsdata that permit Loki to effectively question and retrieve log information. The index serves as a mapping of log entries, enabling quick search operations and optimizing the efficiency of log retrieval.
- Pretend folder. This folder is used to retailer the precise log information. In a single-tenant setup, it could be labeled as “faux,” however it holds the necessary logs generated by your functions.
Now Loki is operating with HA. Utilizing logcli, we also needs to have the ability to confirm the logs by querying towards Loki cases.
Exploring Approaches for Catastrophe Restoration
Loki is a crucial part of our utility stack, accountable for aggregating logs from a number of microservices and displaying them within the internet utility console for end-user entry. These logs should be retained for an prolonged interval — as much as 90 days.
As a part of our catastrophe restoration (DR) technique for the applying stack, making certain the supply and accessibility of logs throughout a catastrophe is essential. If Area-1 turns into unavailable, the functions should proceed to run and entry logs seamlessly. To handle this, we determined to implement excessive availability for Loki by operating two cases in separate areas. If one Loki occasion fails, the occasion within the different area ought to proceed to deal with each learn and write operations for the logs.
We explored three completely different approaches to organising DR for Loki, meaning to allow learn and write capabilities throughout each Area-1 and Area-2, making certain fault tolerance and uninterrupted log administration.
Method 1: Implementing S3 Cross-Area Replication
AWS S3 Cross-Area Replication (CRR) is a characteristic that means that you can robotically replicate objects from one S3 bucket to a different bucket in a special AWS area. That is significantly helpful for enhancing information sturdiness, availability, and compliance by making certain that your information is saved in a number of geographic places. With CRR enabled, any new objects added to your supply bucket are robotically replicated to the vacation spot bucket, offering a backup in case of regional failures or disasters.
In Loki, organising S3 CRR signifies that logs written to a single S3 bucket are robotically duplicated to a different area. This setup ensures that logs are accessible even when one area encounters points. Nevertheless, when utilizing a number of cross-region cases of Loki pointing to the identical S3 bucket, there might be delays in log accessibility as a result of how Loki handles log flushing.
Flushing Logs and Configuration Parameters
When logs are generated, Loki shops them in chunks, that are momentary information constructions that maintain log entries earlier than they’re flushed to the article retailer (on this case, S3). The flushing course of is managed by two crucial parameters: max_chunk_age and chunk_idle_period.
Max Chunk Age:
-
The
max_chunk_ageparameter defines the utmost time a log stream might be buffered in reminiscence earlier than it’s flushed to the article retailer. When this worth is ready to a decrease threshold (lower than 2 hours), Loki flushes chunks extra continuously. This results in larger storage enter/output (I/O) exercise however reduces reminiscence utilization as a result of logs are saved in S3 extra typically. -
Conversely, if
max_chunk_ageis ready to a better worth (higher than 2 hours), it ends in much less frequent flushing, which might result in larger reminiscence consumption. On this case, there may be additionally an elevated danger of knowledge loss if an ingester (the part that processes and writes logs) fails earlier than the buffered information is flushed.
Chunk Idle Interval:
-
The
chunk_idle_periodparameter determines how lengthy Loki waits for brand new log entries in a stream earlier than contemplating that stream idle and flushing the chunk. A decrease worth (lower than 2 hours) can result in the creation of too many small chunks, growing the storage I/O calls for. -
Alternatively, setting a better worth (higher than 2 hours) permits inactive streams to retain logs in reminiscence longer, which might improve retention however could result in potential reminiscence inefficiency if many streams grow to be idle.
This instance exhibits querying logs from one Loki occasion, which is pointed to a CRR-enabled S3 bucket.

Right here, we’re querying the logs from one other Loki occasion, which can be studying logs from the identical CRR-enabled S3 bucket. You may observe the delay of ~2 hours within the logs retrieved.

With this strategy, within the occasion of a catastrophe or failover in a single area, there’s a danger of dropping as much as 2 hours of log information. This potential information loss happens as a result of logs that haven’t but been flushed from reminiscence to the S3 bucket throughout that timeframe will not be recoverable if the ingester fails.
Additionally, Cross-Area Replication is an asynchronous course of, however the objects are finally replicated. Most objects replicate inside quarter-hour, however generally replication can take a few hours or extra. A number of components have an effect on replication time, together with:
- The dimensions of the objects to copy
- The variety of objects to copy
For instance, if Amazon S3 is replicating greater than 3,500 objects per second, then there is perhaps latency whereas the vacation spot bucket scales up for the request price. Subsequently, we needed real-time logs to be accessible from each cases of Loki operating in numerous areas, so we determined towards utilizing AWS S3 Cross-Area Replication (CRR). This alternative was made to attenuate delays and be sure that logs might be retrieved promptly from each cases with out the 2-hour latency related to chunk flushing when utilizing CRR. As an alternative, we targeted on optimizing our setup to allow speedy log entry throughout areas.
Method 2: Using the S3 Multi-Area Entry Level
Amazon S3 Multi-Area Entry Factors (MRAP) supply a world endpoint for routing S3 request visitors throughout a number of AWS Areas, simplifying the structure by eliminating advanced networking setups. Whereas Loki doesn’t instantly help MRAP endpoints, this characteristic can nonetheless improve your logging resolution. MRAP permits for centralized log administration, enhancing efficiency by routing requests to the closest S3 bucket, which reduces latency. It additionally boosts redundancy and reliability by rerouting visitors throughout regional outages, making certain logs stay accessible.
Moreover, MRAP can assist decrease cross-region information switch charges, making it an economical choice. Nevertheless, on the time of this writing, there’s a identified bug that forestalls Loki from successfully utilizing this endpoint. Understanding MRAP can nonetheless be useful for future scalability and effectivity in your logging infrastructure.

Method 3: Using Vector as a Sidecar
We determined to make use of Vector, a light-weight and ultra-fast device for constructing observability pipelines. With Vector, we might gather, remodel, and route logs to AWS S3.
- So, our infrastructure is one S3 bucket and Loki per area.
- Vector can be operating as a sidecar with the applying pods.
- Since EKS clusters are related through a transit gateway, we configured a personal endpoint for each the Loki cases. We don’t need to expose it to the general public because it comprises utility logs.
- Configured vector sources to learn the applying logs, remodel and sink, and write to each the Loki occasion.
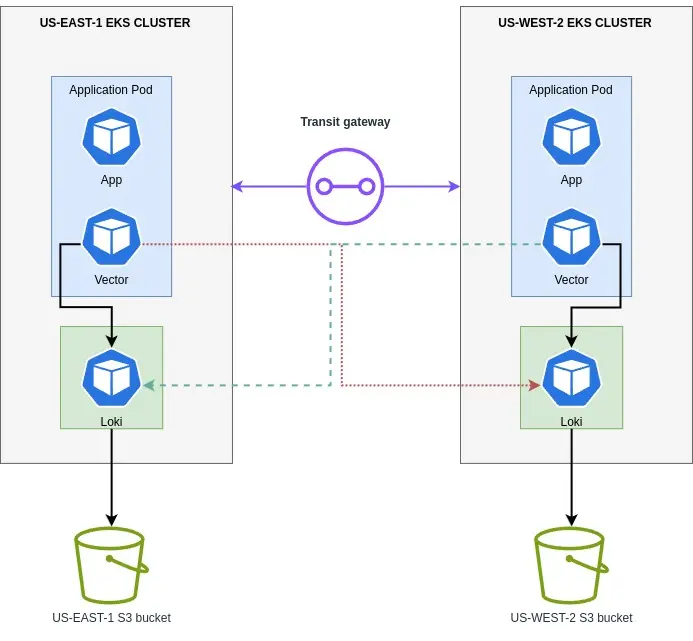
This manner, all logs are ingested and accessible in each Loki, and there’s no want for cross-region replication and/or sharing the identical bucket throughout many areas.
Vector Configuration
Vector Remap Language (VRL) is an expression-oriented language designed for reworking observability information (logs and metrics) in a secure and performant method.
- Sources gather or obtain information from observability information sources into Vector.
- Transforms manipulate, or change that observability information because it passes by way of your topology.
- Sinks ship information onward from Vector to exterior companies or locations.
data_dir: /vector-data-dir
sinks:
# Write occasions to Loki in the identical cluster
loki_write:
encoding:
codec: json
endpoint: http://loki-write.loki:3100
inputs:
- my_transform_id
sort: loki
# Write occasions to Loki within the cross-region cluster
loki_cross:
encoding:
codec: json
endpoint: https://loki-write.aws-us-west-2.loki
inputs:
- my_transform_id
sort: loki
# Outline the supply to learn log file
sources:
my_source_id:
sort: file
embrace:
- /var/log/**/*.log
# Outline the remodel to parse syslog messages
transforms:
my_transform_id:
sort: remap
inputs:
- my_source_id
supply: . = parse_json(.message)On this setup, Vector collects logs from the /var/log/ listing and inner Vector logs. It parses as JSON replaces your entire occasion with the parsed JSON object, and sends them to 2 Loki locations (native and cross-region). The configuration ensures logs are despatched in JSON format and might deal with errors throughout log processing.
Conclusion
The journey to reaching excessive availability (HA) and catastrophe restoration (DR) for Loki has been difficult and enlightening. Via exploring numerous deployment modes and approaches, we’ve gained a deeper understanding of making certain our logging system can stand up to and get better from potential disruptions. The profitable implementation of a Easy Scalable Mode with an S3 backend and the modern use of Vector as a sidecar has fortified our system’s resilience and underscored the significance of proactive planning and steady enchancment in our infrastructure.